watsonx.ai L3 parte 1: Navegación básica e indicación de tiro por cero
¡Aviso! ¡El material del cuestionario se marcará así!
Watsonx.ai es un componente central de watsonx, la plataforma de datos e IA de IBM preparada para empresas y diseñada para multiplicar el impacto de la IA en toda la empresa. El componente watsonx.ai permite a las empresas entrenar, validar, ajustar y desplegar modelos tradicionales y generativos de IA.
NOTA: Si está completando este laboratorio en un entorno de taller/aula de IBM, la instancia de watsonx.ai se compartirá entre todos los estudiantes. Deberá haber sido invitado a una cuenta en la nube de IBM y añadido a un proyecto watsonx.ai con el formato de nombre
VEST-Labs-{Location}-{MMDD}donde Location es la ubicación y MMDD indica el mes y el día de su taller.
Consola Watsonx.ai
Empezaremos con una rápida explicación de la consola de watsonx.ai. Primero, sigue estas instrucciones para acceder a la página de inicio de watsonx.ai.
La página de inicio tendrá un aspecto similar al siguiente:
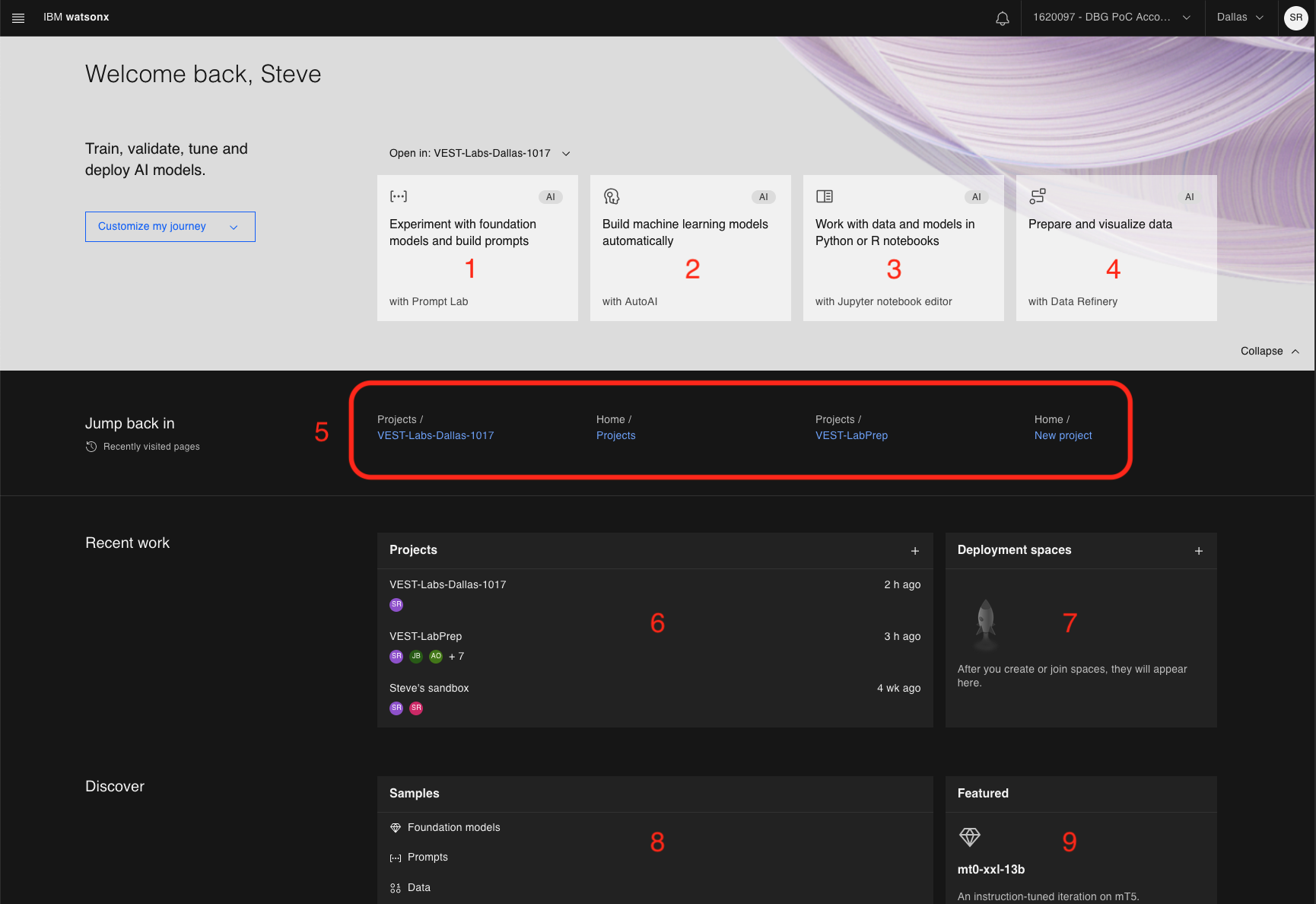
Estas son las distintas regiones de la consola.
- Acceda a la consola del Laboratorio de prompts. Puede experimentar con diferentes modelos, probar sus prompts, ajustar los parámetros del modelo y guardar sus sesiones de prompts. Este es el objetivo de este laboratorio.
- Cree trabajos de AutoAI para construir automáticamente modelos de aprendizaje automático (ML).
- Cree cuadernos Python o R nuevos o trabaje con los existentes directamente en la interfaz de usuario de watsonx.ai.
- Cargue los datos y prepárelos (mediante Data Refinery) para el consumo de la IA.
- Enlaces rápidos a páginas visitadas recientemente
- Muestra una lista de proyectos. Para el nivel gratuito de watsonx.ai, verá un proyecto por defecto llamado
{username}'s sandbox. - Espacio de despliegue: aquí es donde puede añadir activos en un solo lugar para crear, ejecutar y gestionar despliegues.
- Una colección de muestras. Un gran lugar para explorar si eres nuevo en watsonx.ai.
- Modelos destacados: watsonx.ai destacará varios modelos de cimientos y casos de uso.
Laboratorio Prompt - Navegación básica
¡Pregunta sobre las capacidades de Prompt Lab!
Si aún no lo ha hecho, acceda a la interfaz de usuario de Prompt Lab haciendo clic en el siguiente mosaico de la página de inicio de watsonx.ai:
Si es la primera vez que accede al laboratorio de consultas de esta cuenta, se le pedirá que reconozca algunos puntos relacionados con los modelos generativos de IA y, opcionalmente, que realice una visita guiada.
Tanto si decides hacer el recorrido como si no, deberías acabar en la interfaz de usuario del laboratorio, ¡que es por donde vamos a empezar!
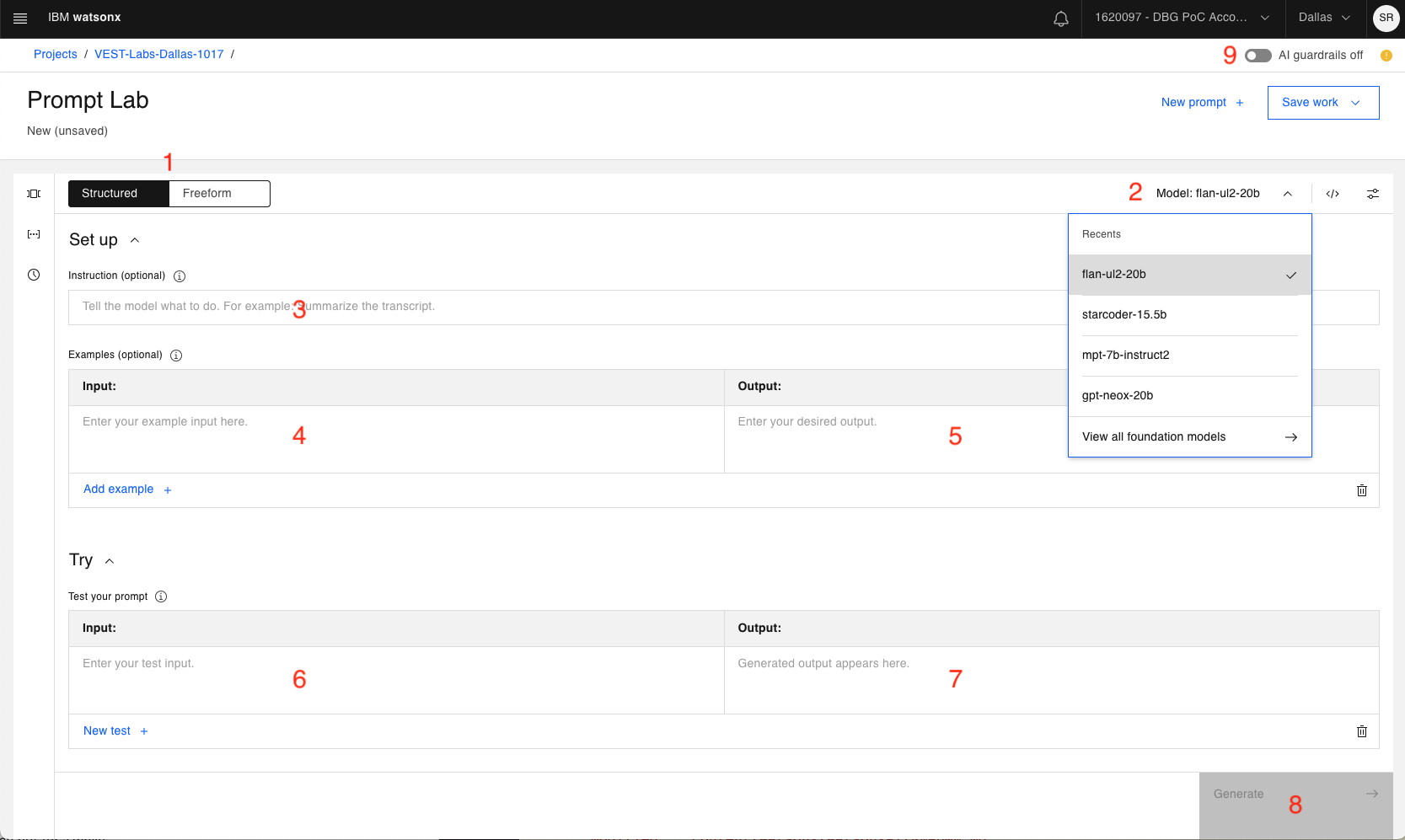
Este laboratorio cubrirá un subconjunto básico de las capacidades de Prompt Lab. Para una explicación inicial de la interfaz de usuario, vamos a caminar a través de las secciones numeradas:
-
Posibilidad de alternar entre editores de prompts Structured o de prompts Freeform.
a. El aviso Structured es el predeterminado y proporciona directrices para la creación de prompts.
b. Los prompts de Freeform muestran un área de texto para interactuar con el modelo de cimentación. Probablemente lo prefieran los usuarios más experimentados.
-
Utilice el desplegable para elegir entre distintos modelos de cimientos.
-
Una primera instrucción que se enviará al modelo de base. Opcional, ya que puede que no siempre necesites una instrucción de nivel superior.
-
Muestra de entrada que puede combinarse con la Muestra de salida (punto 5) para "enseñar" al modelo cómo responder adecuadamente a su pregunta.
-
Muestra de salida (correspondiente a la entrada del punto 4).
Los modelos de fundamentos pueden considerarse máquinas de probabilidades: generan resultados eligiendo la siguiente ficha más probable, dadas todas las fichas anteriores.
Existen muchas técnicas para mejorar los resultados de un modelo básico. Una de ellas consiste en "enseñar" al modelo proporcionándole muestras de entrada y salida (lo que se denomina un "disparo"). Los tipos de disparos incluyen:
Indicación de disparo cero: no se proporciona entrada/salida
Un solo ejemplo: un solo ejemplo de entrada/salida
Varios ejemplos: varios ejemplos. -
En la sección Try se introduce la consulta.
-
Aquí es donde se mostrará la salida generada.
-
Haga clic en el botón Generate cuando esté listo para que el modelo de cimentación reciba sus entradas.
-
Watsonx.ai proporciona guardarraíles de IA. Por defecto, está desactivado. Puedes activarlo para evitar posibles entradas y salidas de texto perjudiciales (como expresiones de odio, abuso o prejuicios).
Otros controles, como la actualización de los parámetros de configuración de la inferencia, se tratarán a medida que avancemos en los laboratorios.
Exploración de los modelos de cimentación con un indicador de tiro cero
Hay 6 modelos de cimientos de código abierto disponibles en watsonx.ai a partir del 4T2023.
Se añadirán más a medida que se examinen otros modelos de fundación y se consideren apropiados para watsonx.ai.
También hay 2 modelos de IBM disponibles, los modelos granite-13b-chat-v1 y granite-13b-instruct-v1, que se tratarán en detalle en una futura iteración de este laboratorio.
-
En el panel izquierdo haga clic en el icono de muestra, ]⃞[.
¡Pregunta sobre las agrupaciones de preguntas de muestra!
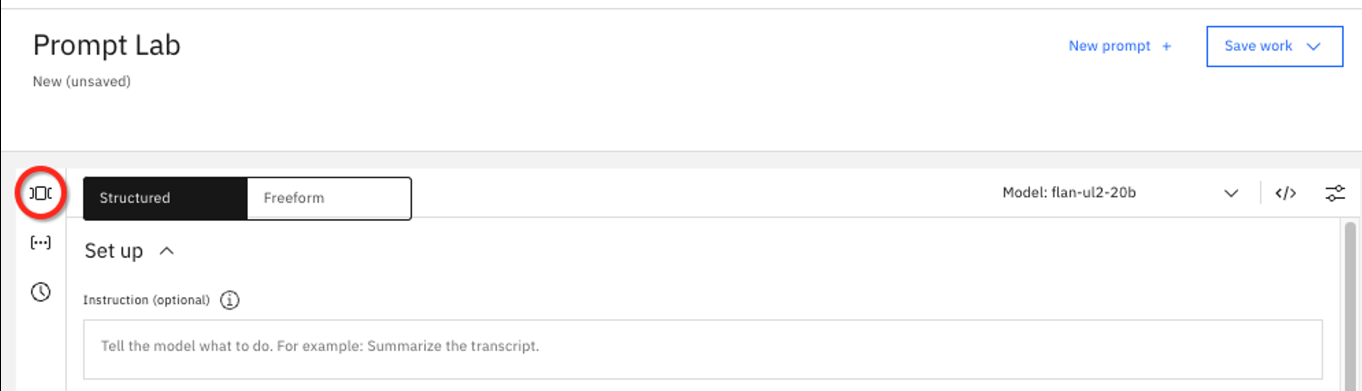
Watsonx.ai proporciona ejemplos de instrucciones agrupadas en categorías como:
- Summarization
- Classification
- Generation
- Extraction
- Question Answering
- Code
Estos son los 6 principales casos de uso de la IA generativa. Para las siguientes pruebas utilizaremos la muestra de generación de correos electrónicos de marketing de la sección Generación.
-
Seleccione la generación de correo electrónico de marketing de la lista de ejemplos de la izquierda. Esta solicitud pide un mensaje de marketing de 5 frases basado en las características proporcionadas.
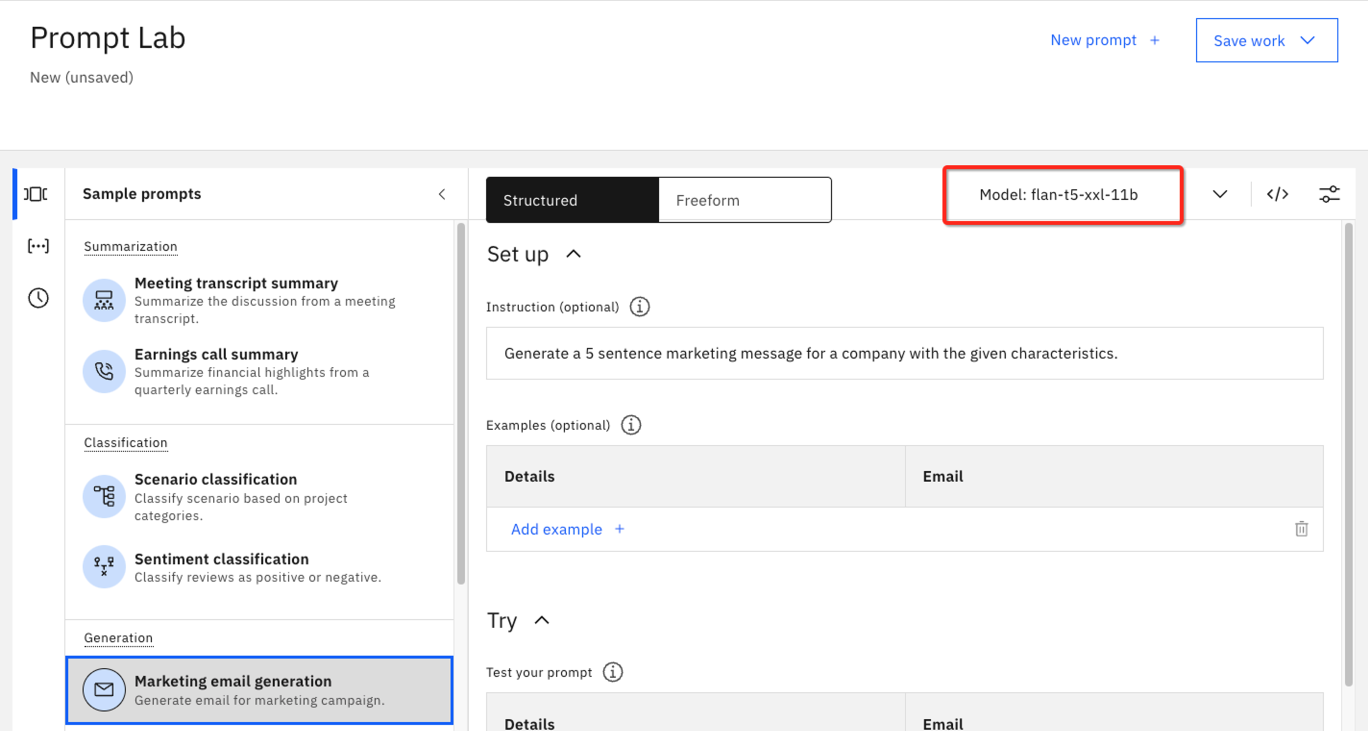
Observe cómo el modelo flan-t5-xxl-11b se seleccionó automáticamente para este caso de uso de ejemplo. Watsonx.ai selecciona el modelo que tiene más probabilidades de ofrecer el mejor rendimiento. Sin embargo, esto no es una garantía, y en esta parte del laboratorio, vamos a explorar diferentes modelos en este mismo símbolo del sistema.
-
Haga clic en el campo Detalles de la sección Probar para ampliar el cuadro y ver el texto completo de este ejemplo.
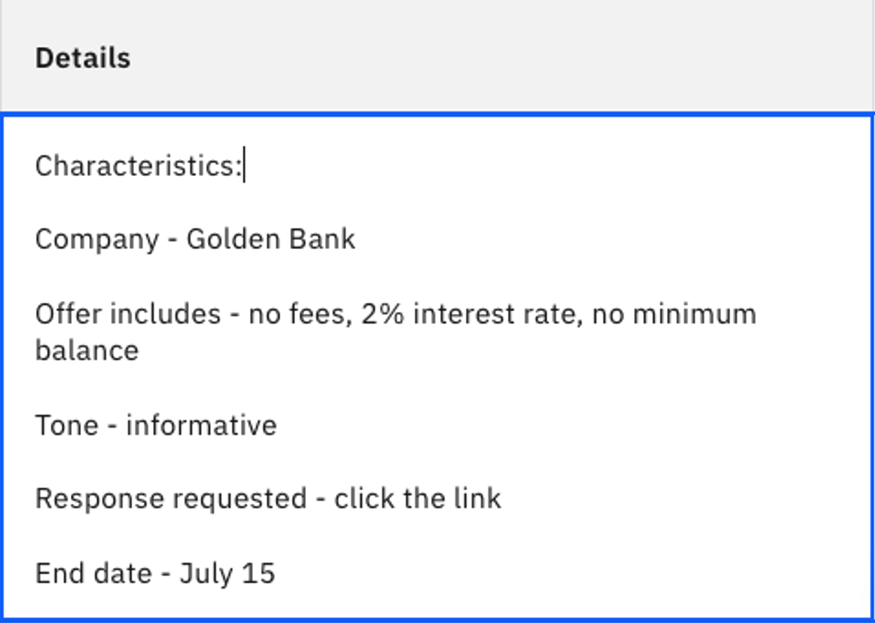
Si no puede encontrar este ejemplo de consulta, o si el contenido ha cambiado, puede introducir:
- Para instrucciones
Generate a 5 sentence marketing message for a company with the given characteristics.- Más información en la sección Probar
Characteristics: Company - Golden Bank Offer includes - no fees, 2% interest rate, no minimum balance Tone - informative Response requested - click the link End date - July 15txt -
Haga clic en Generar para ver la salida del correo electrónico.

Se trata de un resultado razonable, pero quizá no ideal.
Nota: Se trata de una solicitud de disparo cero, ya que no proporcionamos ninguna muestra de entrada/salida.
-
Mire a la izquierda del botón Generar y verá un texto similar al siguiente:

Nota: Todo el texto utilizado en las secciones Instrucciones y Detalles pasa a formar parte del mensaje. Para este modelo, el máximo de tokens permitidos para una transacción es 4096. Esto varía según el modelo.
La moneda de un LLM son los tokens. Los tokens no se asignan 1 a 1 con palabras. Para obtener más información y ver la tokenización en acción, consulte esta página de referencia
-
Intentemos hacer lo mismo con otro modelo de cimentación. Haga clic en el menú desplegable del modelo de cimentación para elegir otro modelo.
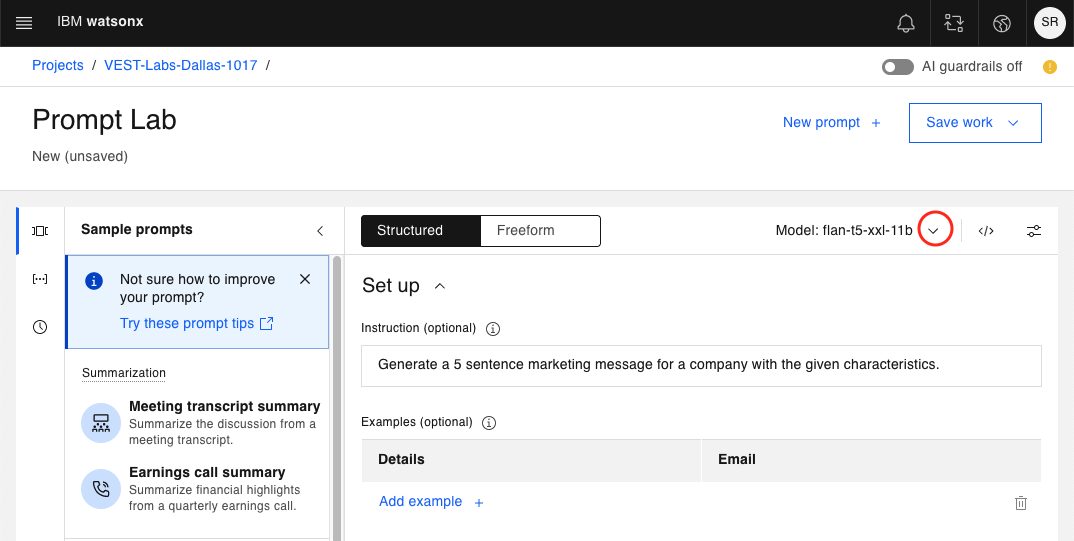
Si ha utilizado anteriormente otros modelos, los verá en la sección Recientes. Si no, sólo verás tu modelo actual y una opción para Ver todos los modelos de fundaciones.
-
Haga clic en Ver todos los modelos de cimientos
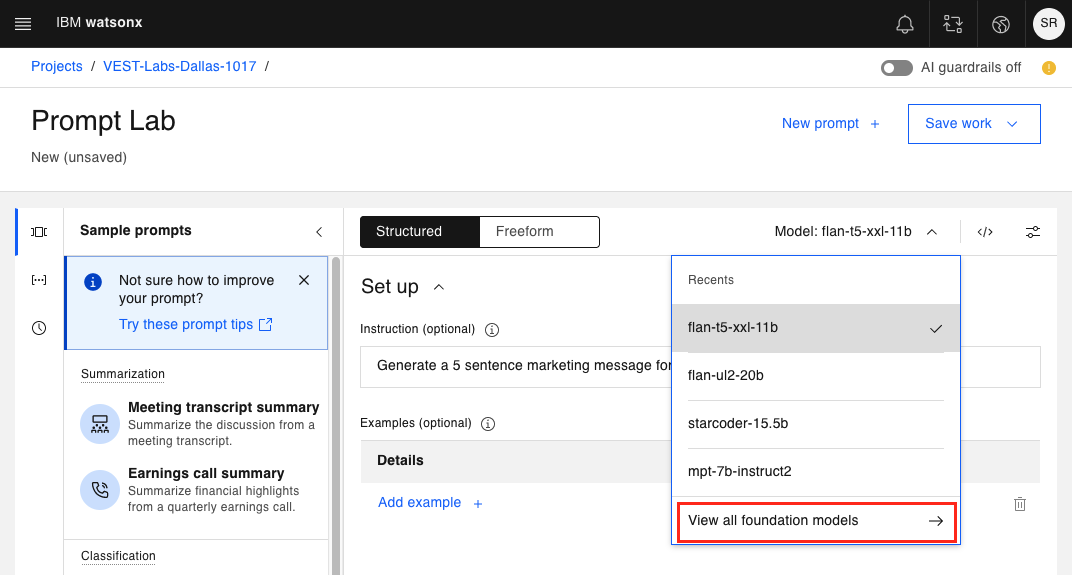
Aparecerá el siguiente panel de modelos de cimientos disponibles.
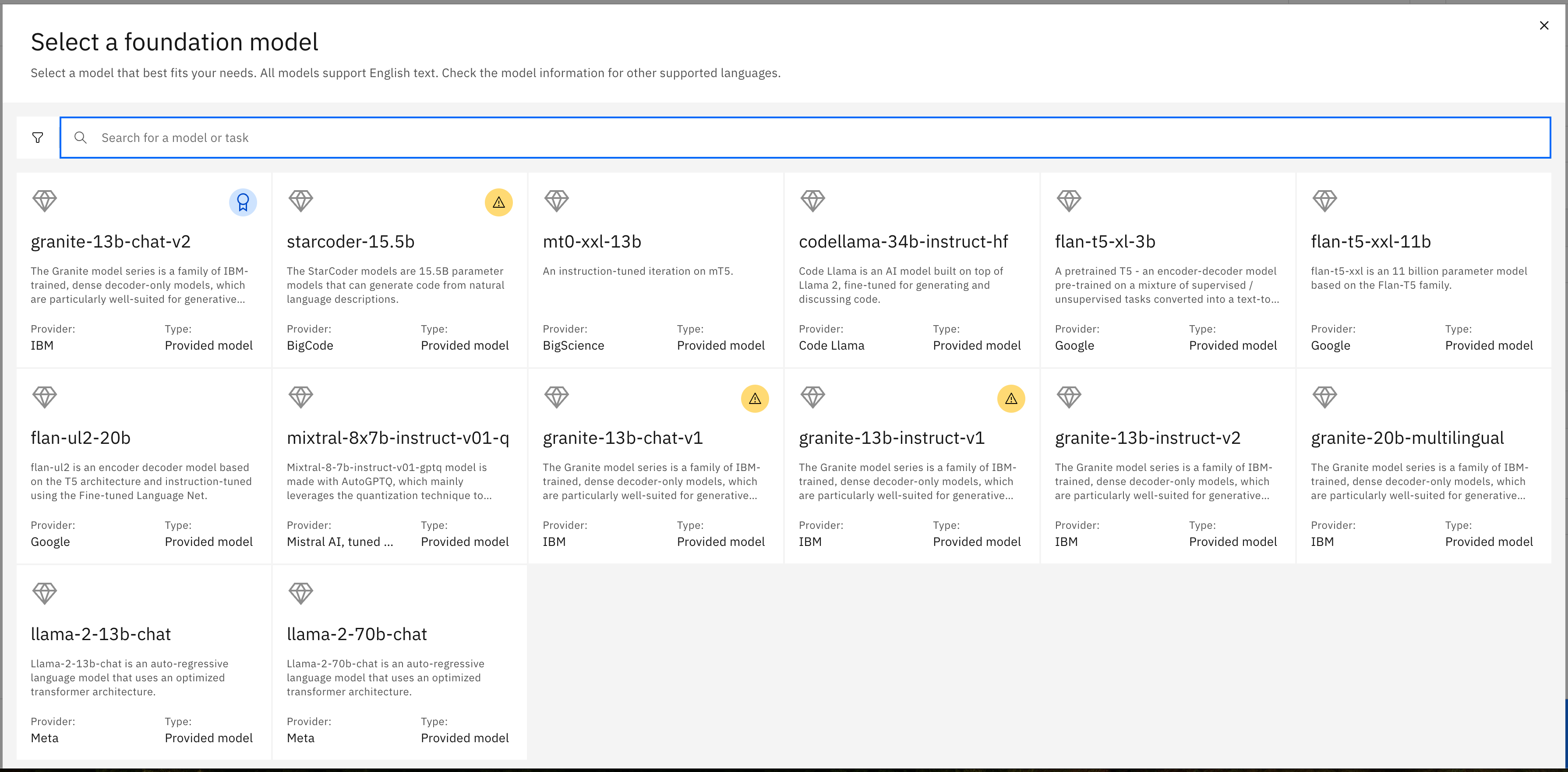
Al seleccionar cualquiera de estas opciones, se mostrará más información en forma de ficha de modelo.
-
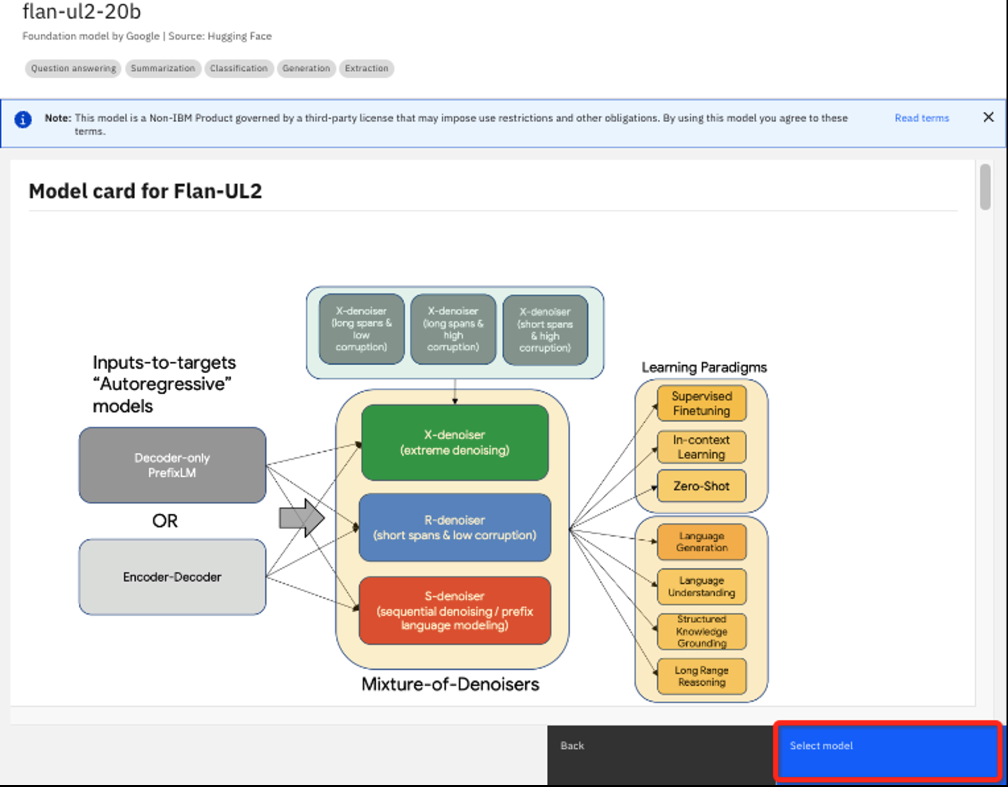
Elija el modelo flan-ul2-20b para ver la ficha del modelo.
Aquí puede encontrar detalles como la forma en que se entrenó el modelo, cómo puede haber sido ajustado previamente y otros detalles que probablemente sean más útiles para los científicos de datos experimentados. Se trata de un modelo similar a flan-t5-xxl-11b, pero mucho más grande. El "20b" indica 20.000 millones de parámetros frente a 11.000 millones.
Haga clic en el botón Seleccionar modelo para elegir el modelo flan-ul2-20b.
-
Compruebe que ahora está utilizando el modelo flan-ul2-20b y haga clic en Generar.
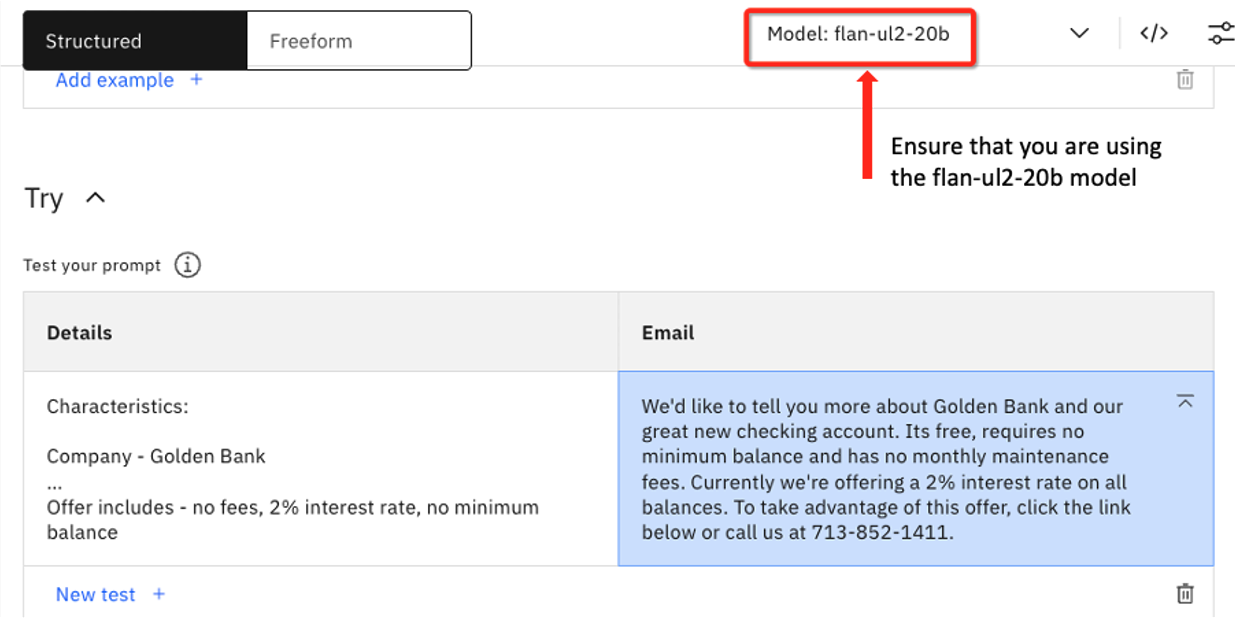
La terminación es la siguiente:
We'd like to tell you more about Golden Bank and our great new checking account. Its free, requires no minimum balance and has no monthly maintenance fees. Currently we're offering a 2% interest rate on all balances. To take advantage of this offer, click the link below or call us at 713-852-1411.
Nota: el modelo más grande alucinó con un número de teléfono del banco. He aquí un ejemplo en el que un modelo de fundación más grande obtuvo peores resultados que el más pequeño.
-
Repita los pasos 6-9, esta vez seleccionando el modelo mpt-7b-instruct2. Debería ver la siguiente salida generada:

NOTA: Este modelo también alucinó, añadiendo una fecha del 12 de diciembre de 2021. Esto se debe probablemente a que este modelo en concreto se ha entrenado con datos hasta 2021.
-
Cambie al modelo llama-2-70b-chat e intente la misma pregunta una vez más. Debería ver la siguiente salida:
 Este modelo alucinó con una url para el banco e incluyó una fecha de julio, pero omite el importante detalle del 15 de julio.
Este modelo alucinó con una url para el banco e incluyó una fecha de julio, pero omite el importante detalle del 15 de julio.
Ingeniería de prompts - actualización de un aviso de disparo cero
Ahora experimentemos alterando nuestra instrucción de tiro cero para ver si podemos lograr un mejor resultado. Nuevamente trabajaremos con el ejemplo de generación de correo electrónico de Marketing, pero modificando las instrucciones.
-
Abra una nueva sesión de Prompt Lab para asegurarse de que cualquier experiementation anterior en la sesión actual no afecta a los resultados del laboratorio.
-
Una vez más, abra el panel de aviso de muestra en el lado izquierdo y elija Generación de correo electrónico de marketing. Elija el modelo flan-t5-xxl-11b si aún no lo ha especificado. Haga clic en Generar.
-
Ahora añada el siguiente texto en el cuadro de texto Detalles: "No añada ninguna información adicional", y haga clic de nuevo en Generar.
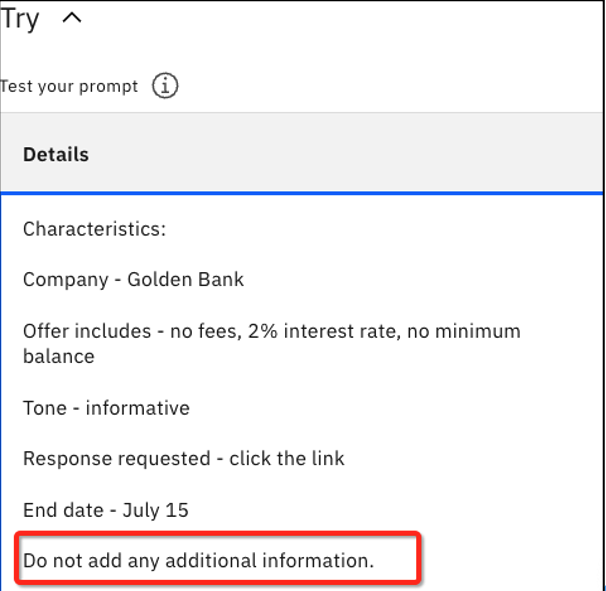
Ahora debería ver que se ha eliminado la parte inventada de "Ahora puede controlar todas sus cuentas de Golden Bank desde casa".
-
Cambia al modelo flan-ul2-20b. Recuerda que en el laboratorio anterior este modelo alucinó y proporcionó un número de teléfono inventado. Haz clic en Generar para ver cómo responde este modelo al mensaje actualizado.
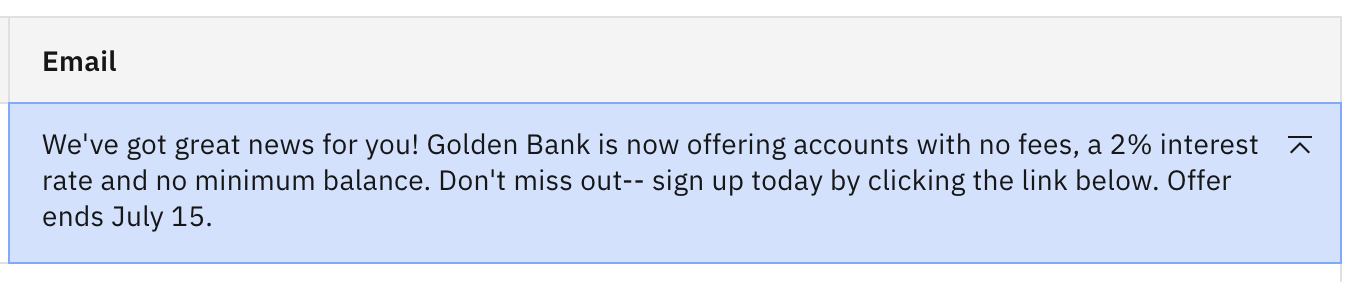
Se puede ver que la instrucción extra no fue suficiente para frenar la creatividad de este modelo. Probemos con algo más explícito.
-
Vuelva al campo de entrada Detalles. En lugar de "No añada ninguna información adicional", cambie la instrucción por "No invente ningún número de teléfono ni página web". Haga clic en Generar. Debería ver lo siguiente.
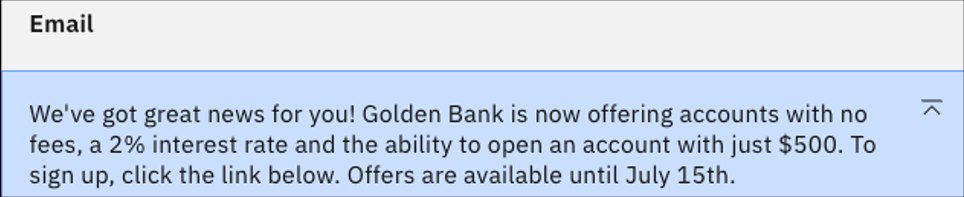
El sitio web ha desaparecido, pero hay una nueva adición de un mínimo de cuenta de $ 500. Es probable que esto se deba a la formación sobre datos de instituciones financieras en las que esa cantidad es un mínimo común.
-
Para sofocar la creatividad de flan-ul-20b, actualice la nueva instrucción para que diga "No incluya ninguna otra información no proporcionada anteriormente". Haga clic en Generar.
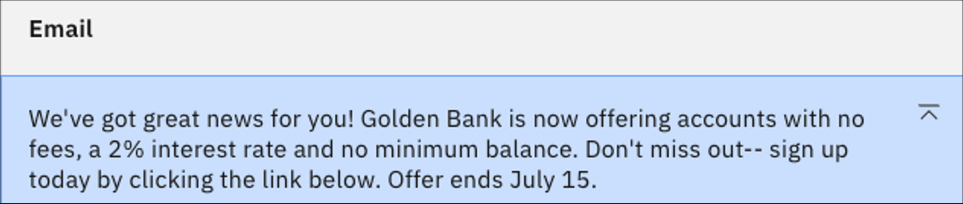
Ahora por fin tenemos salida sin ninguna alucinación. Pero veamos cómo funciona la misma indicación para un modelo mucho más grande.
-
Utilice el mismo indicador, pero cambie al modelo de 70 mil millones de parámetros llama-2-70b-chat y haga clic en Generar. Debería ver algo similar a lo siguiente:
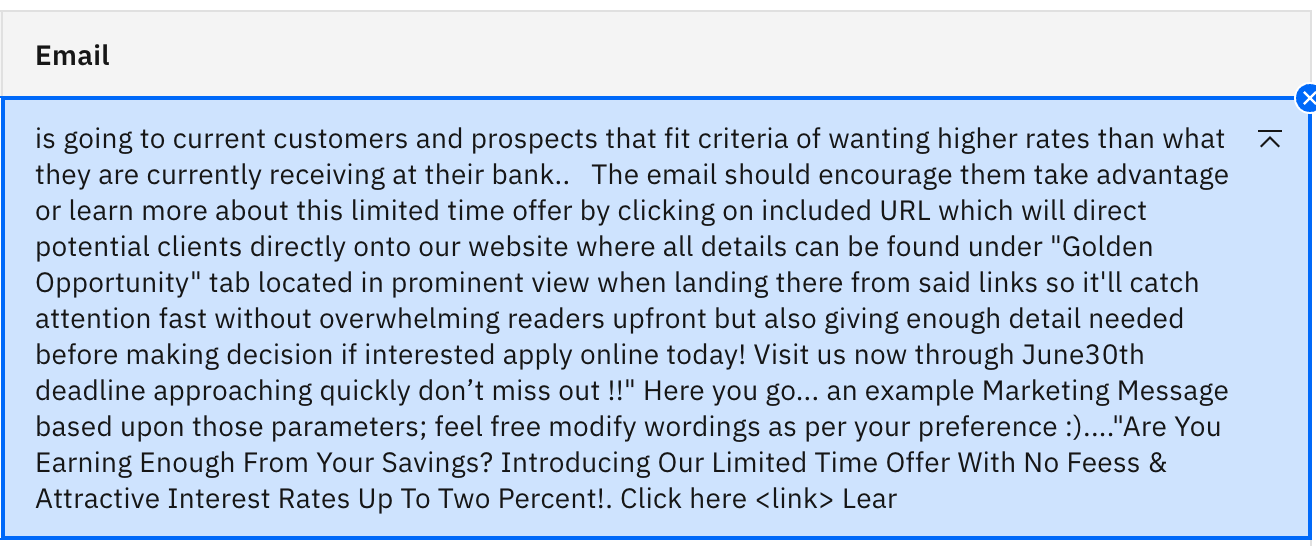
¡Vaya! El mismo impulso que funcionó bien para flan-ul-20b ha empujado al modelo llama-2 en la dirección opuesta. Se ha vuelto básicamente incomprensible. Observe también que la salida no se detuvo de forma natural, sino por el límite de 200 tokens generados. Hablaremos más de esto en el próximo laboratorio.
-
Para realizar una prueba final, antepongamos al principio de la última instrucción "Crear un correo electrónico sucinto." y hagamos clic en Generar

Esto hace una gran diferencia en la longitud de la salida, todavía alucina una url y hace un error de fecha. Un modelo de este tamaño es mucho más creativo e impredecible. Para algunas tareas, como nuestro correo electrónico de marketing, puede ser mejor utilizar un modelo más pequeño.
Resumen de laboratorio
- Aprendimos a utilizar una muestra de aviso con diferentes modelos de cimientos.
- Incluso en el caso de los prompts de disparo cero, la entrada de prompts puede modificarse para obtener una mejor respuesta de los modelos de cimentación.
- Una fundación no está "respondiendo" a una pregunta explícita, sino buscando ampliar/generar la siguiente ficha más probable basándose en todas las entradas anteriores, incluida la pregunta inicial.
- Diferentes modelos pueden funcionar mejor con diferentes indicaciones.
- Los modelos más grandes suelen ser más creativos y necesitan instrucciones más explícitas.
- Es tentador pensar que los modelos más grandes son mejores, pero lo más sensato es adaptar el modelo a su caso de uso, que puede ser más adecuado con un modelo más pequeño.
- Las grandes diferencias en los resultados de los modelos ponen de relieve la importancia de probar varios modelos para encontrar el que mejor se adapte a la tarea.