Ingestión de datos
Ingestión de datos
La ingesta de datos es el proceso de importar y cargar datos en watsonx.data. Existen varios métodos para introducir datos en watsonx.data, entre ellos:
• La opción Crear tabla a partir de archivo de la página Gestor de datos
• La edición independiente, no para desarrolladores, de watsonx.data incluye una pestaña Trabajos de ingestión en la página Gestor de datos, donde se pueden leer datos de un bucket de almacenamiento de objetos de origen e ingestarlos en una tabla. Sin embargo, como este laboratorio utiliza la edición para desarrolladores, no está disponible para su uso aquí.
• Instalación de la herramienta de línea de comandos ibm-lh y uso de comandos para crear un trabajo de ingesta de archivos desde un almacenamiento de objetos compatible con S3 o un sistema de archivos local.
• Cargar los archivos de datos de una tabla en un bucket de almacenamiento de objetos (si aún no residen en él), registrar el bucket con watsonx.data y crear una tabla sobre los archivos mediante SQL.
En esta sección utilizará la consola MinIO para cargar un archivo de datos Parquet en el almacenamiento de objetos y, a continuación, creará una tabla en él utilizando SQL en Presto.
- Descarga el archivo aircraft.parquet desde aquí.
- Si aún no tiene abierta la consola MinIO, ábrala en una nueva ventana del navegador. Utilice las credenciales (clave de acceso y clave secreta) que anotó anteriormente.
Dado que está cargando un fichero de datos que no está "envuelto" en el formato de tabla Iceberg, necesita utilizar un catálogo Hive. Utilizará el catálogo existente hive_data que está asociado al bucket hive-bucket.
- Haga clic en la fila del cubo hive-bucket.

- En el panel hive-bucket, haga clic en el botón Crear nueva ruta.
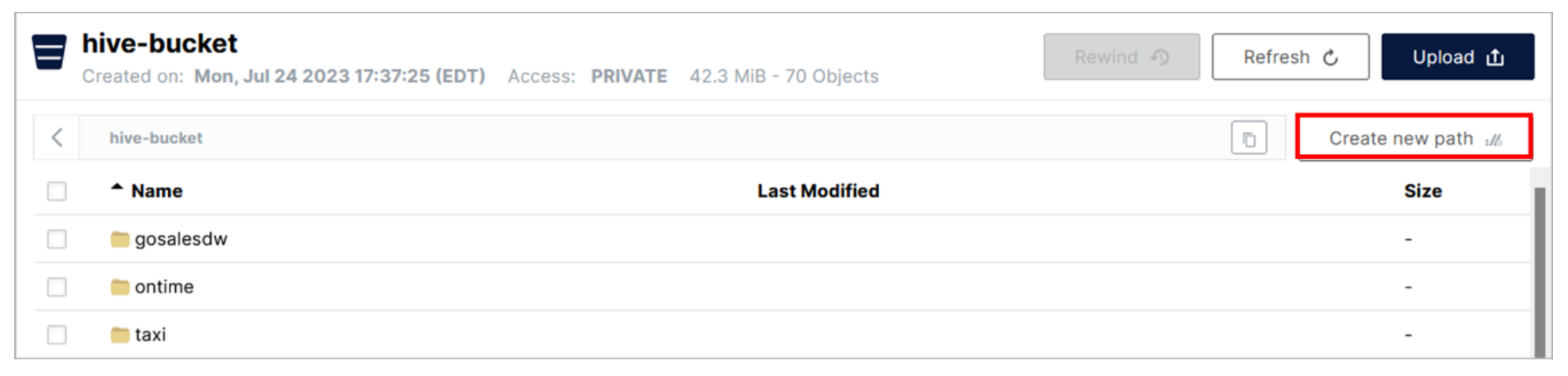
- En la ventana emergente Elegir o crear una nueva ruta, introduzca myschema2/aircraft para la Nueva ruta de carpeta. A continuación, haga clic en el botón Crear.

Esto va a crear carpetas anidadas bajo el cubo actual. La carpeta de nivel superior (myschema2) debe coincidir con el nombre del esquema que va a crear más tarde, y la siguiente carpeta (aircraft) debe coincidir con el nombre de la tabla que va a crear más tarde.
- Se le pedirá que cargue un archivo. Haga clic en el botón Cargar situado en la parte superior derecha y, a continuación, en Cargar archivo.

Nota: También tiene la opción de cargar una carpeta. Si ya dispone de un conjunto de archivos en carpetas organizadas por esquema y tabla, podría cargar toda la carpeta (en cuyo caso no tendría que crear una nueva ruta para la tabla como hizo anteriormente, ya que la ruta ya está reflejada en la carpeta que se está cargando).
- Localiza, selecciona y carga el archivo aircraft.parquet que descargaste anteriormente.
- Haga clic en el icono Descargas/Cargas para cerrar el panel Descargas/Cargas.
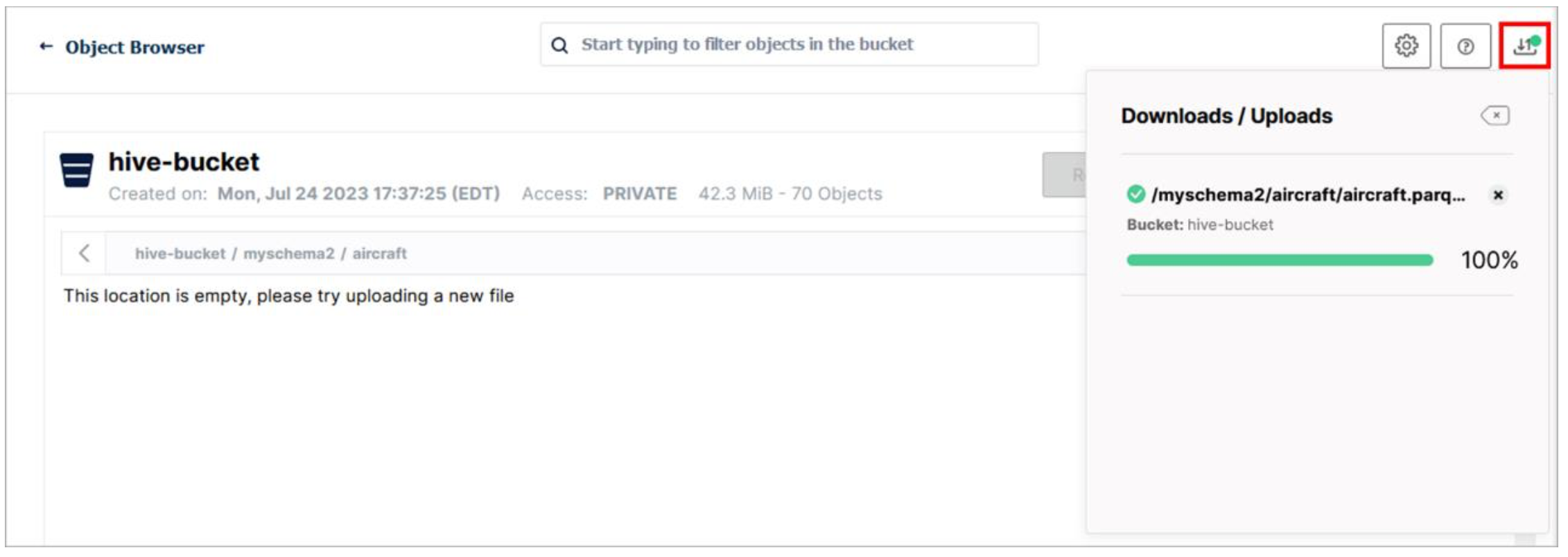
- Si la carpeta aparece vacía, haga clic en el botón Actualizar situado en la parte superior derecha. Si la carpeta sigue apareciendo vacía, suba un nivel hasta la carpeta principal (myschema2) y vuelva a bajar hasta esta carpeta (aircraft). Si esto sigue sin funcionar, actualiza la ventana del navegador.

Ahora debería aparecer el archivo, como en la imagen siguiente.

- Cierra la ventana del navegador de la consola MinIO porque ya no necesitas utilizarla.
Ahora creará un esquema y una tabla que coincidan con el archivo que ha cargado. Utilizará la CLI de Presto, pero también puede utilizar la página del espacio de trabajo de consulta en la interfaz web watsonx.data.
- Abra una ventana de comandos de terminal en el servidor watsonx.data como usuario root.
- Ejecute el siguiente comando para abrir un terminal interactivo Presto CLI.
/root/ibm-lh-dev/bin/presto-clibash
- Ejecute la siguiente sentencia SQL para crear el esquema myschema2 (basado en el catálogo/bucket que se está utilizando y el nombre de la carpeta del esquema que especificó al cargar el archivo en el almacenamiento de objetos anteriormente; el nombre del esquema no tiene por qué coincidir, pero es más fácil de gestionar de esta manera).
create schema hive_data.myschema2 with (location = 's3a://hive-bucket/myschema2');
bash- Ejecute la siguiente sentencia SQL para crear la tabla de aircraft.
create table hive_data.myschema2.aircraft (tail_number varchar, manufacturer varchar, model varchar) with (format = 'Parquet', external_location='s3a://hive-bucket/myschema2/aircraft');
bash- Compruebe que la tabla de aircraft se ha creado correctamente consultando el número de filas que contiene.
select count(*) from hive_data.myschema2.aircraft;
bashDebería haber 13.101 filas devueltas. Su tabla acaba de leer los datos del archivo que cargó en el almacenamiento de objetos.
- Salga de la CLI de Presto ejecutando el siguiente comando.
quit;bash
- Abra la interfaz de usuario de watsonx.data en una ventana del navegador (si aún no la tiene abierta).
- Seleccione el icono Gestor de datos en el menú de la izquierda.
- Expanda el catálogo hive_data para ver el nuevo esquema que ha creado (myschema2).

Nota: Si no ve el esquema en la lista, sitúe el puntero del ratón sobre el extremo derecho de la línea del catálogo hive_data hasta que aparezca el icono Actualizar. Haga clic en el icono Actualizar. Ahora debería ver el esquema listado como en la imagen anterior.
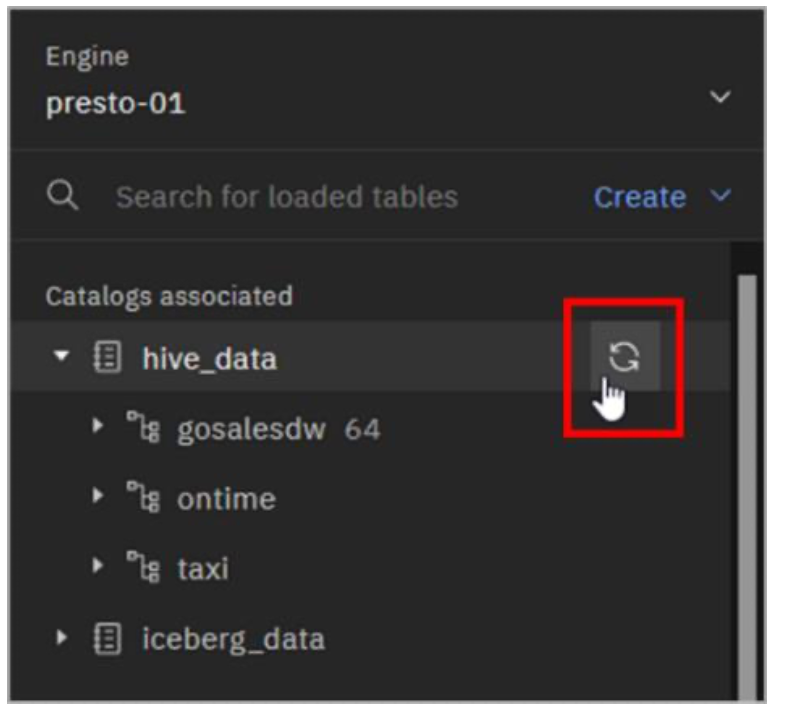
- Expanda el esquema myschema2 para ver la nueva tabla que ha creado (aircraft).

La tabla que acaba de crear a través de la CLI de Presto -que se basa en un archivo de datos que cargó en el almacenamiento de objetos- es visible a través de la interfaz de usuario de watsonx.data. Esta es una de las ventajas de disponer de un metastore compartido. En el futuro, cualquier motor de consulta que se asocie al catálogo hive_data también podrá trabajar con esta tabla.
Enhorabuena, has llegado al final del laboratorio 105.
Haga clic en, laboratorio 106 para iniciar el siguiente laboratorio.