Descarga de datos de un almacén de datos
Descarga de datos de un almacén de datos
Con watsonx.data, las empresas pueden descargar datos que realmente no necesitan estar en el almacén a un almacenamiento de objetos de menor coste. Con motores adaptados, los costes de almacenamiento de datos pueden reducirse descargando cargas de trabajo de un almacén de datos a watsonx.data. En concreto, las aplicaciones que necesitan acceder a estos datos pueden consultarlos a través de Presto (o Spark). Esto incluye poder combinar los datos descargados con los datos que permanecen en el almacén. Esta sección mostrará un ejemplo de cómo se puede hacer esto con Db2 (pero los pasos son equivalentes para otros productos de almacén de datos).
Además, los motores externos que soportan el formato de tabla abierta Iceberg también pueden trabajar directamente con los datos en el almacenamiento de objetos de watsonx.data. Los últimos Db2 y Netezza también pueden participar en el ecosistema de watsonx.data, accediendo directamente a los datos de lakehouse en el almacenamiento de objetos (al igual que Presto y Spark).
En el Laboratorio anterior usted registró un entorno Db2 existente con watsonx.data (llamándolo Db2DW) y creó un catálogo para él llamado db2catalog.
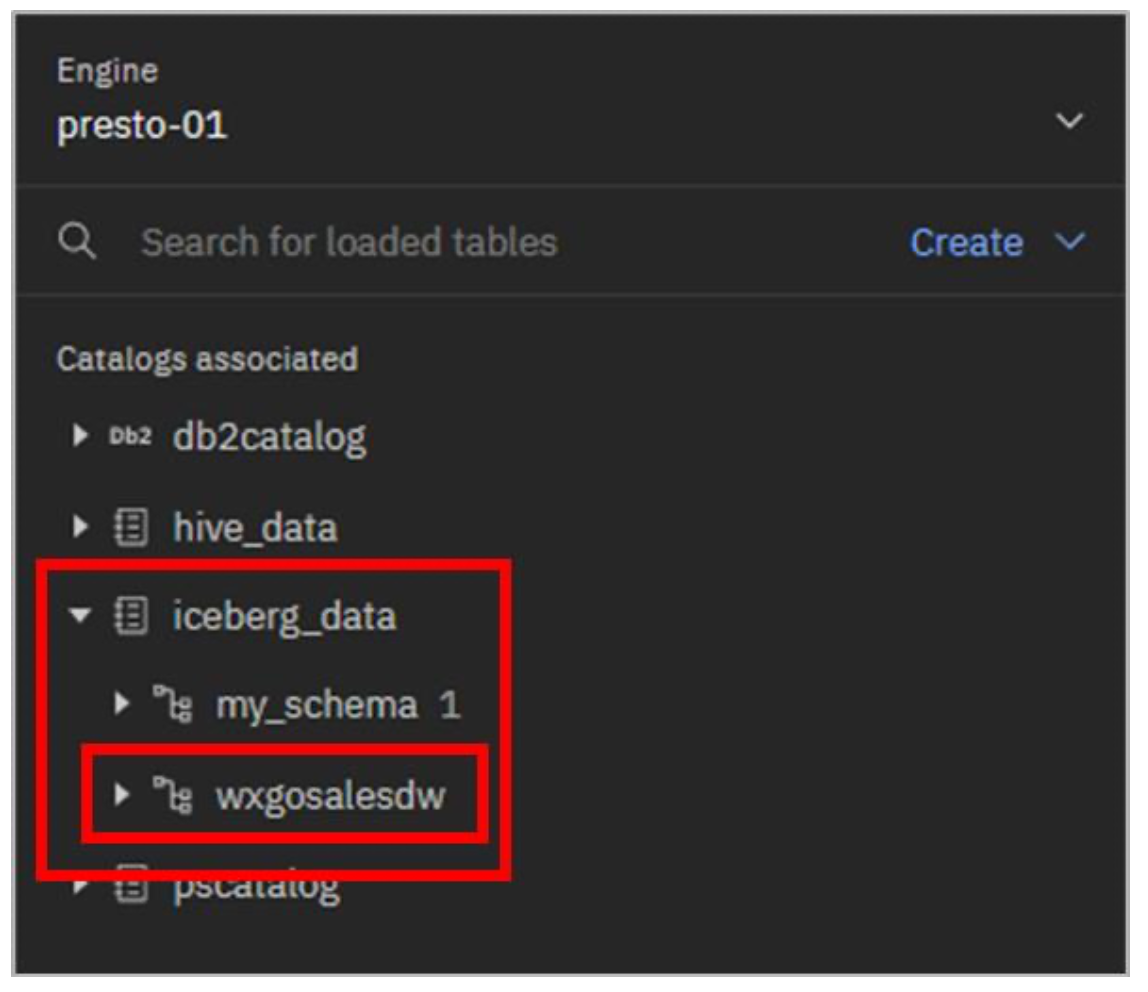
En este escenario de ejemplo, vas a "mover" la tabla gosalesdw.sls_sales_fact de Db2 al almacenamiento de objetos de watsonx.data. Se creará como una tabla Iceberg, en un nuevo esquema que creará llamado wxgosalesdw, gestionado por el catálogo iceberg_data.
- Seleccione el icono Gestor de datos en el menú de la izquierda.
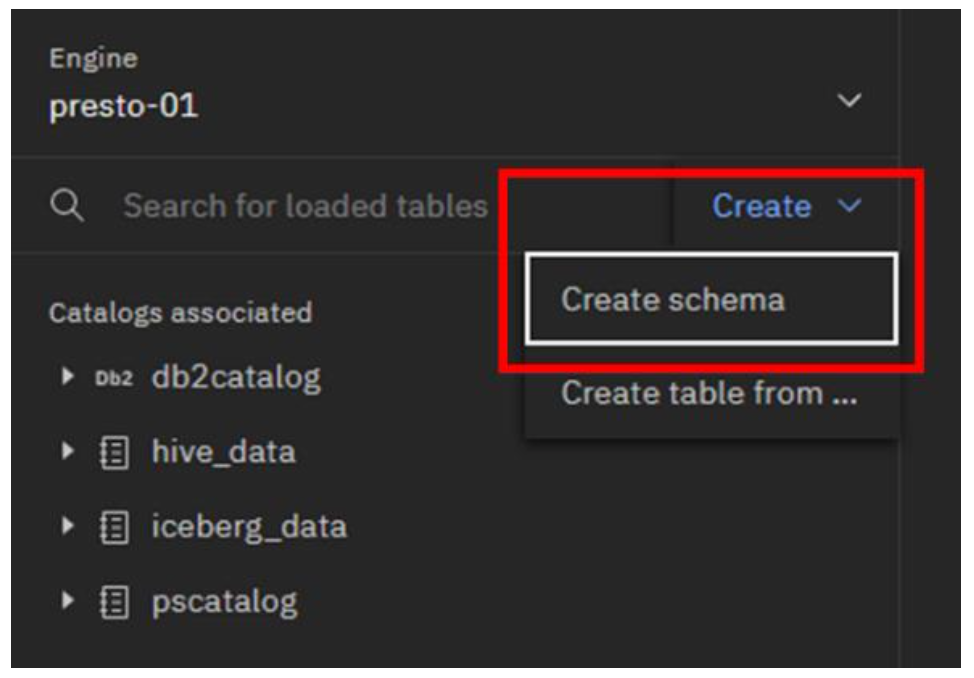
- Vaya a la parte superior del panel de navegación y haga clic en el menú desplegable Crear. Seleccione Crear esquema. (Nota: En estos pasos se utiliza la interfaz web, pero también puede crear un esquema a través de SQL).
-
En la ventana emergente Crear esquema, seleccione/introduzca la siguiente información y, a continuación, haga clic en el botón Crear:
- Catálogo: iceberg_data
- Nombre: wxgosalesdw

- Despliegue el catálogo iceberg_data. El nuevo esquema debería aparecer en la lista.
- Seleccione el icono Espacio de trabajo de consulta en el menú de la izquierda.
Para crear una nueva tabla con la misma definición de tabla que la tabla original, puede utilizar la sentencia SQL CREATE TABLE AS SELECT (CTAS).
- Copie y pegue el siguiente SQL en la hoja de cálculo SQL. Haga clic en Ejecutar en presto-01.
create table iceberg_data.wxgosalesdw.sls_sales_fact as select * from db2catalog.GOSALESDW.SLS_SALES_FACT;
bash
El resultado que aparece en la parte inferior de la hoja de cálculo muestra el número de filas que se han insertado desde la tabla de origen a la nueva tabla.

En un escenario real, se eliminaría la tabla del almacén de datos. Sin embargo, para mantener el conjunto de datos de ejemplo gosalesdw intacto en su entorno, no lo hará aquí.
Como prueba, puede ejecutar una consulta federada que combine la nueva tabla en el almacenamiento de objetos con las tablas existentes en Db2.
- Copie y pegue el siguiente SQL en la hoja de cálculo SQL. Haga clic en Ejecutar en presto-01.
select pll.product_line_en as product, sum(sf.quantity) as total
from
db2catalog.GOSALESDW.SLS_PRODUCT_DIM as pd,
db2catalog.GOSALESDW.SLS_PRODUCT_LINE_LOOKUP as pll,
hive_data.gosalesdw.sls_sales_fact as sf
where
pd.product_key = sf.product_key
and pll.product_line_code = pd.product_line_code
group by pll.product_line_en
order by product;
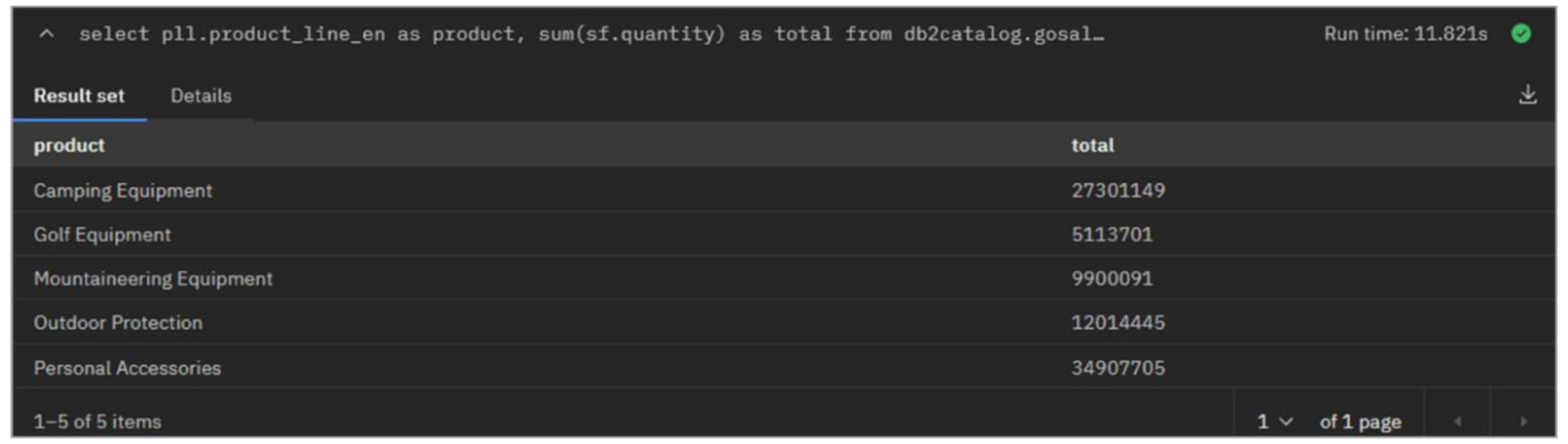
bashEsta consulta empresarial calcula las ventas totales para cada una de las líneas de productos de alto nivel. La salida debe ser similar a la imagen de abajo.
Enhorabuena, has llegado al final del laboratorio 107.
Haga clic en, laboratorio 108 para iniciar el siguiente laboratorio.