watsonx.ai L3 Part 2: Model parameters and prompting for output formats
Heads Up! Quiz material will be flagged like this!
This is Part 2 of the watsonx.ai L3 badge lab. In the previous lab, we experimented with different foundation models and saw how tweaks to a zero-shot prompt can make a big difference in the generated output.
In this lab, we will explore other techniques for getting the best results from a foundation model.
Modifying parameters
In this lab, we will continue working in the Prompt Lab and experiment with configurable model parameters. If necessary, navigate back to the watsonx.ai home screen, and enter the Prompt Lab UI.
If you have already been working in the Prompt Lab, open a new Prompt Lab session
-
In the Prompt Lab UI, select the ]⃞[ icon from the left panel to bring up the list of sample prompts. Click the Marketing email generation sample from the Generate section. Use the flan-ul2-20b model if not already specified.
-
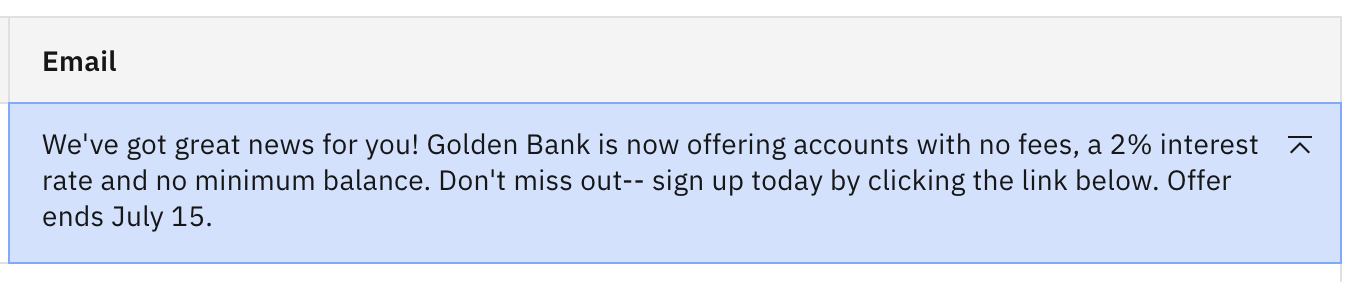
We will again start with a slightly modified prompt. Edit the Details field in the Try section, adding
Do not add any additional information.as the final instruction. Click Generate.You should see the same output as before.
-
Next, we will modify some inference parameters to see the impact on the generated output. But first, let's discuss what the configurable parameters do. Open the settings panel by clicking the Model parameters icon shown below.
-
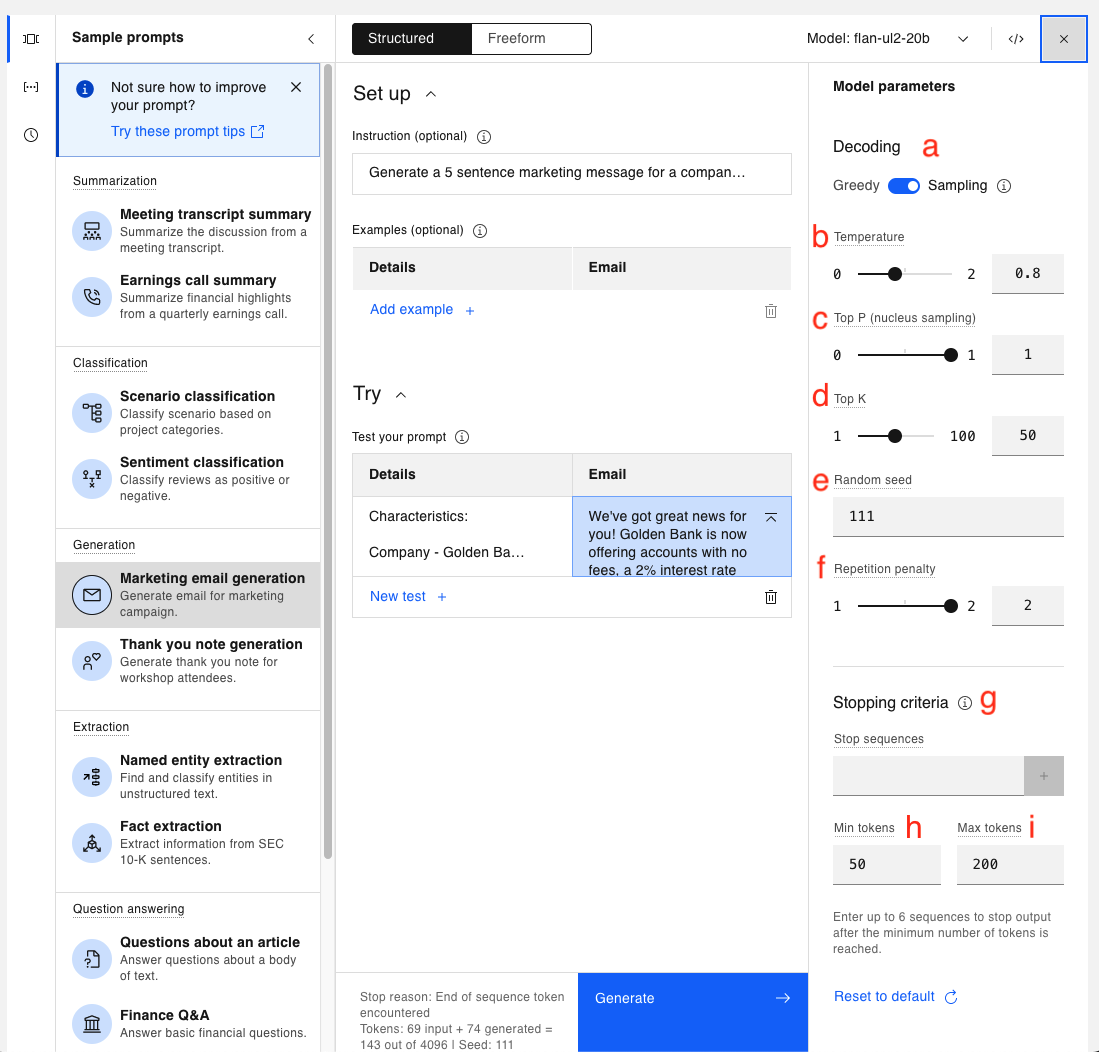
This opens a list of parameters than can be updated. All models utilize the same inference parameters. Let's explain the purpose of each.
Quiz question related to model parameters!
-
a. Greedy vs. Sampling Decoding - This is how the model chooses the tokens for output. The first 4 parameters below (b through e) are only visible when in Sampling mode.
-
In Greedy mode, the model selects the highest probability tokens at every step of decoding, and a model is less creative in that mode.
-
In Sampling mode, the model chooses the next token from a pool of the most probable next tokens, so there is more creativity, but also a larger risk that the output may be nonsensical.
-
-
b. Temperature – a floating point number ranging from 0.0 (which causes the model to operate in the same manner as if Greedy decoding was selected) and 2.00 (which is maximum creativity).
-
The higher the value of Temperature, the more “creative” the model would be.
-
The default value is typically 0.7 but is set to 0.8 in this case. This means the model is allowed certain creativity.
-
-
c. Top P (nucleus sampling) - a floating point number ranging from 0.0 to 1.0. At a high level, when generating a completion, a model calculates the probability of the next word based on all the previous words. Top P decides whether the model will always pick the most likely outcome, or allow more randomness for the next words. Top P sampling chooses from the smallest possible set of "next" words whose cumulative probability exceeds the value provided for Top P.
-
d. Top K - an integer from 1 to 100. Unlike Top P, Top K does not look at the probability of the tokens. Instead, the model chooses the next word from the Top K most likely tokens for the next piece of output.
-
Top K = 3, means the model will choose randomly from the top 3 most likely next words.
-
The higher the value of Top K, the more random the outcome would be.
-
-
e. Random seed - an integer in the range 1 to 4,294,967,295. In Sampling mode, with everything else remaining the same, updating the Random seed will yeild different outputs.
-
If the Random seed remains the same, you should get back the same results, which is why we leave the value the same for these labs.
-
In short, Random seed is helpful for the replicability of experiements.
-
-
f. Repetition penalty - a value between 1 and 2 (a setting of 1 allows repetition, and 2 prohibits it). This is used to counteract a model's tendency to repeat the prompt text verbatim or get stuck in a loop in generating the same output.
-
g. Stop sequences - sequences of characters (text, special characters, carriage return, etc) used as a stop indicator by the model. The stop sequence itself will still be included in the model output, but that will be the last piece of output.
-
h. Min tokens - an integer that specifies the minimum number of tokens in the model's output.
-
i. Max tokens - an integer that specifies the maximum number of tokens in the model’s output. Sometimes when the generated output looks incomplete, your Max tokens value may be too low.
Keep in mind, you are charged or limited based on the number of tokens used, so be careful setting the Max tokens higher than necessary.
-
-
The values you see are the default values for the Marketing email generation sample use case. Let's play with the values and see how some changes impact our output. Leave the current prompt in place, and change the value of Temperature from 0.8 to 0.4.
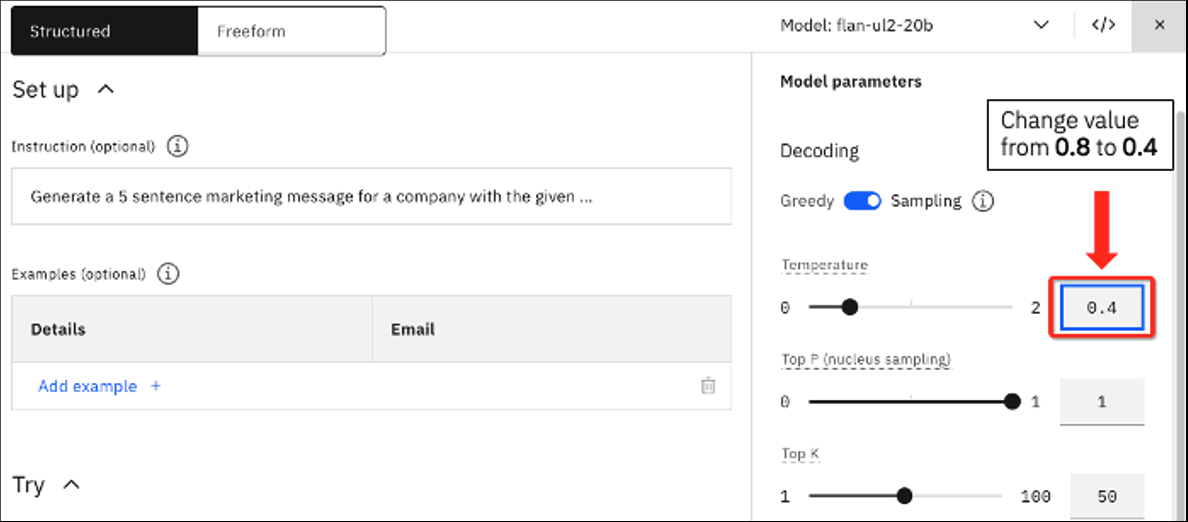
Click Generate. You should now see the following output.
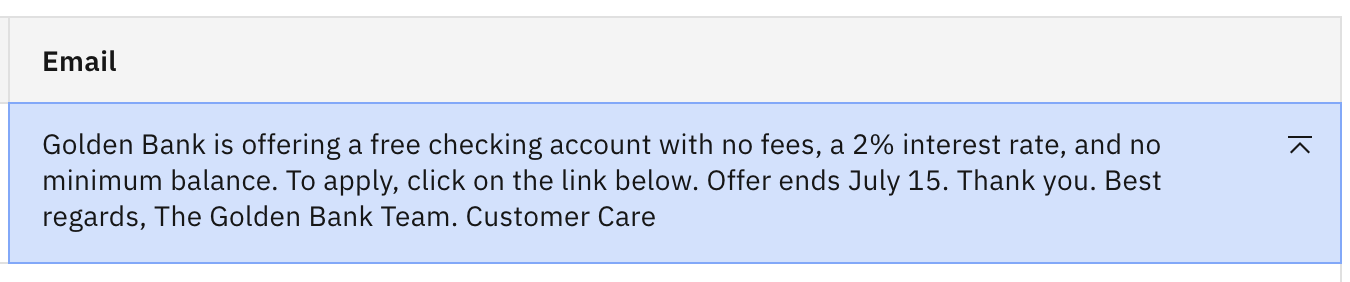
Notice by lowering the creativity the output changed quite a bit, and we now have a rather lengthy thank you ending.
-
Reset the Temperature value to 0.8, and lower the Top P value from 1 to 0.5. This means the next token will be chosen randomly from the top number of tokens whose collective probability is greater than 0.5. Click Generate again.
You should see very similar output. In this case, lowering the Top P value had roughly the same effect as lowering the Temperature.
-
Now let's update the Top K value to 25 and reset Top P to 1.0.
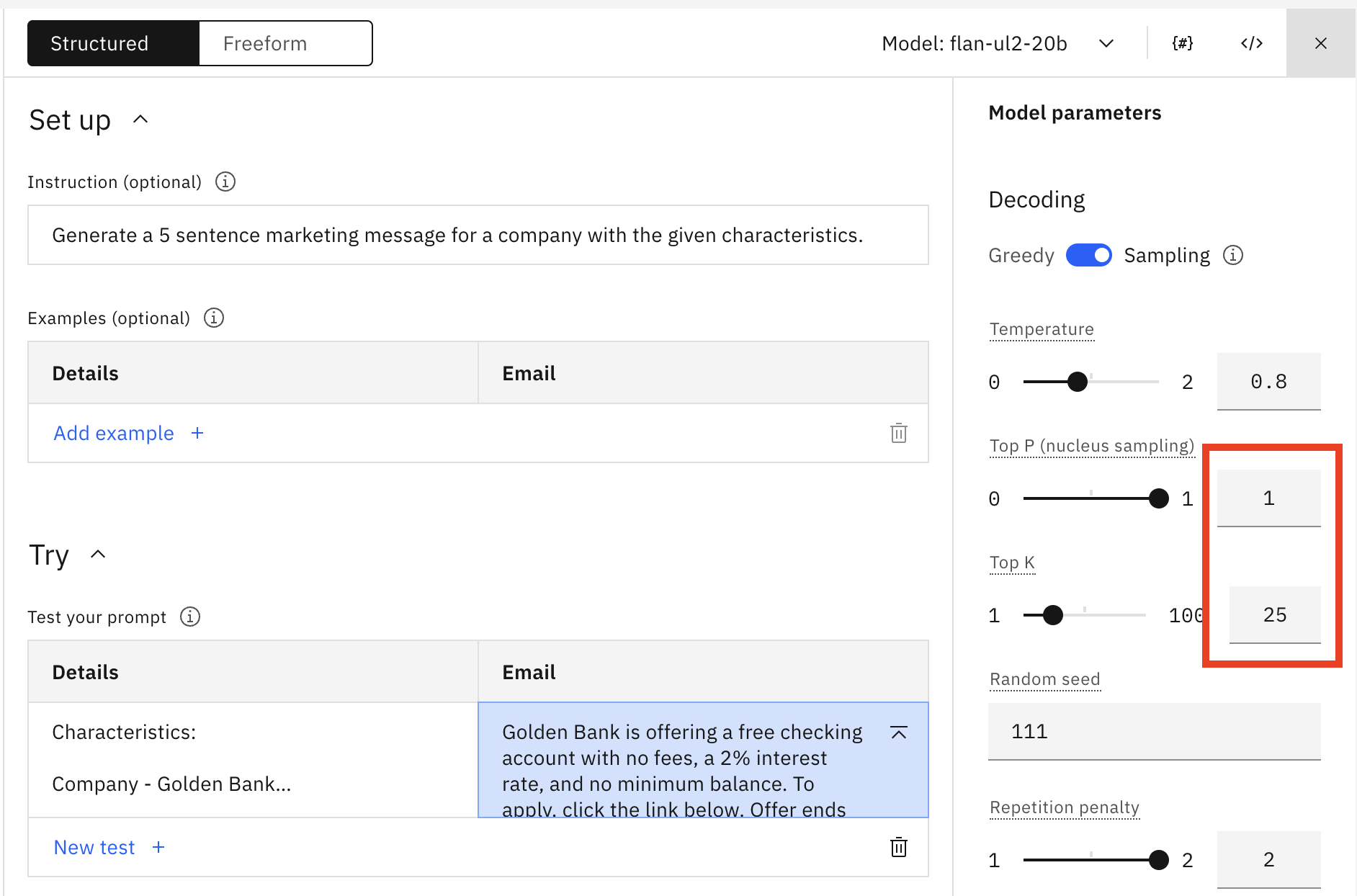
Click Generate. You should see the following.
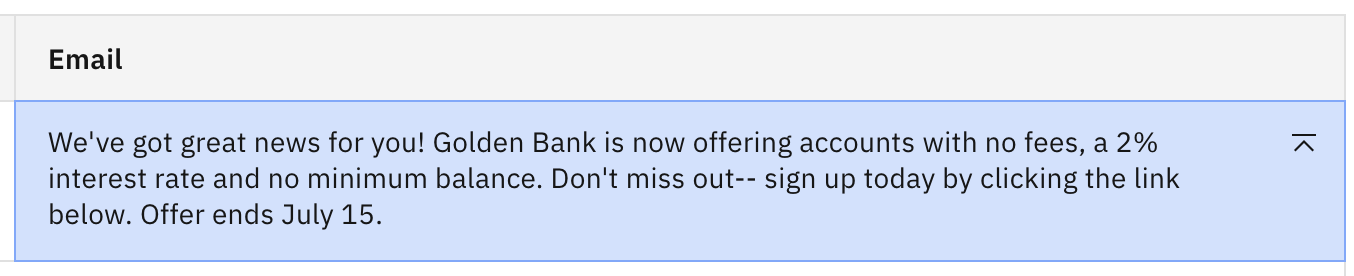
The output has reverted to the original. The model is now choosing the next token from the 25 tokens with the highest probability, so clearly the update to Top P resulted in fewer than 25 options for the next token.
-
Continue lowering the Top K value. Notice that if you lower it quite far (to about 10) you should see pretty good output with accurate info.
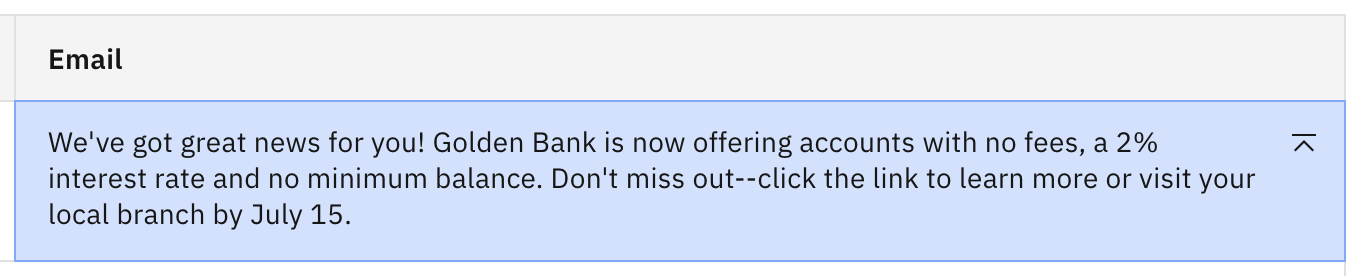
Why the difference? This is best illustrated with an example. Consider a model has determined the following set of potential next tokens for a particular input:
TokenProbabilityT10.16T20.15T30.14T40.13T50.12T60.11T70.10T80.09In this case when you set:
-
Top P = 0.5, the model chooses randomly among T1, T2, T3, and T4 (because the probabilities sum up to > 0.5).
-
Top K = 50, the model chooses randomly among all 8 of the tokens (as 8 < 50)
Thus, for this case, you need to lower Top K to 4 to have a similar effect as Top P = 0.5 so both settings are choosing among the top 4 tokens.
-
Prompting for different output formats
When prompting an LLM, it's often beneficial to get the output in a specific format. For readability, or for streamlining an integration to another tool.
Prompting for Lists
Remember that a foundation model does not read and interpret a prompt like a human. Rather, it consumes a series of tokenized words and calculates the best next token. The concept of a list is easy for a human to understand. Here we will see how some LLMs respond.
-
Open a new Prompt Lab session and select the Freeform tab instead of the default Structured tab. Choose "Switch mode" when prompted to Switch to freeform mode.
Note: In Freeform mode, you still have access to all the examples, models, and configuration, but there is no structural guide for the prompt.
-
Open the Model parameters panel. In Freeform mode, the parameter defaults look like the following if you have not selected a prompt sample.
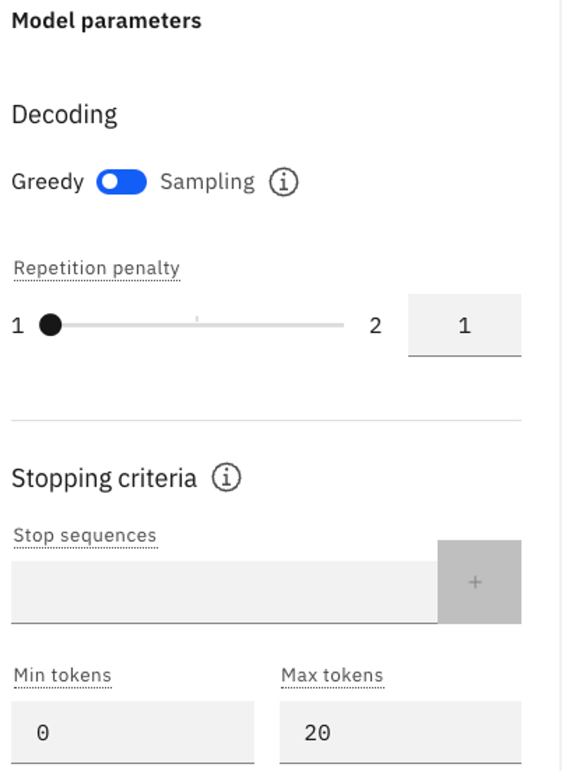
-
Verify that you are using Greedy decoding, and change the value of Max tokens to 100.
-
Ensure that you are using the flan-ul2-20b model. Copy and paste the following text in the input field:
The following paragraph is a consumer complaint. Read the following paragraph and list all the issues. I called your helpdesk multiple times and every time I waited 10-15 minutes before I gave up. The first time I got through, the line got cut suddenly and I had to call back. This is just not helpful. When I finally got through like after 3 days (yes, 3 days) your agent kept going over a long checklist of trivial things and asking me to verify, after I repeatedly told the agent that I am an experienced user and I know what I am doing. It was a complete waste of time. After like an eternity of this pointless conversation, I was told that an SME will contact me. That – was 2 days ago. What is the problem with your support system? The list of issues is as follows:txtClick Generate. You should see output similar to the following:

Note the following:
- The model did not output a list.
- The model just repeated the input text word by word.
- The output terminates due to the 100 token limit.
The flan models (both the flan-ul2-20b and the flan-t5-xxl-11b) seem to percieve "list" as an instruction to recount what it was previously told. -
One common method for getting list output is to guide the model by starting the list. Remove the previous output and add a "1." to the last line of your prompt text. The last two lines should look like:
The list of issues is as follows: 1.txtClick Generate. You should see output like the following:

This is only a slight improvement. The flan models do not seem well-suited for generating a list with zero shot prompts.
-
Change the model to the granite-13b-instruct-v2 model. Remove the "1." from the prompt and click Generate. You should see something close to the following:

This looks more like what a human would expect. For this kind of request, the granite-13b-instruct-v2 model is much better than the flan models. Additionally, the model correctly interpretted that the customer was frustrated with the support system, although this was not explicitly stated.
Prompting for JSON output
When using LLM's programmatically it can be advantageous to retrieve generated data in a format that is easily consumed by the programming language. Let's attempt to use the Prompt Lab to generate a simple JSON file.
-
Open a new Prompt Lab session in the default Structured mode and ensure that you are using the flan-ul2-20b model.
-
Ensure that you are using Greedy mode and set Max tokens to 100.
-
Copy and paste the following to the Input field under the Try section
Create a JSON file output with the following information name: Joe age: 25 Phone: 416-1234-567 Phone: 547-4034-240 Address: City: Markham, Street: Warden Avenue, Postal Code: L6G 1C7txtClick Generate. The flan-ul2-20b model returns the following:
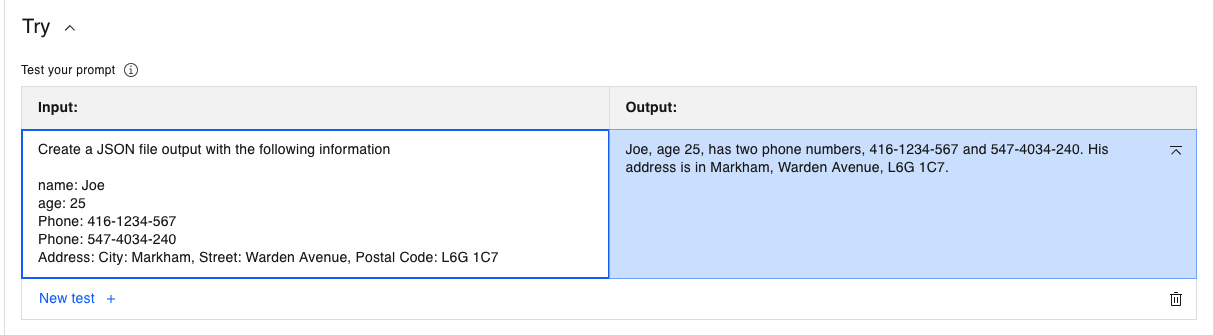
The flan model responded with natural language output, which is the strength of the flan model. But clearly this is not the requested JSON.
-
Select the granite-13b-instruct-v2 model and click Generate. You should see the following output.
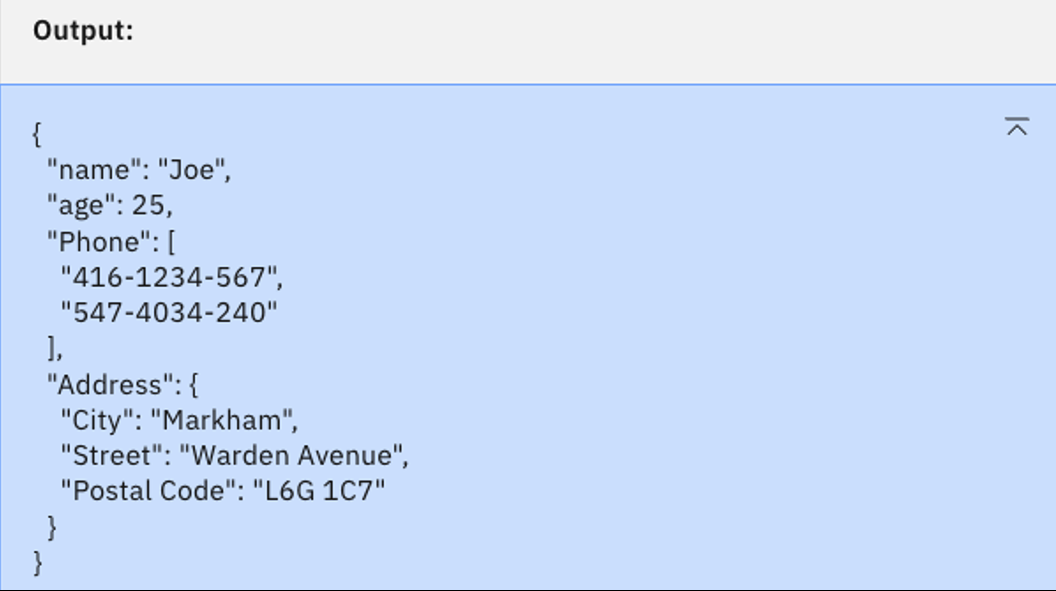
This is the valid JSON we are looking for. Again, the smaller granite-13b-instruct-v2 model seems best for the use case.
-
Now let's try with the codellama-34b-instruct-hf model, which is trained for code generation. Select this model and click Generate. You should see:

Here we have a valid JSON, but the indentation has some issues, and there is a lot of white space.
-
If we still wanted to go with the codellama-34b-instruct-hf, we can use Stop sequences to clean up the output. Open the Model parameters panel and enter
}↵}in the Stop sequences text box. (You can type a carriage return by pressing the Enter or Return key on your keyboard.) Let's also add an instruction to format the output. The updated instructions should read:Create a JSON file output with the following information, and please format it properly.Quiz question on stop sequences!
You should see the following, then click the blue + button to add the sequence.
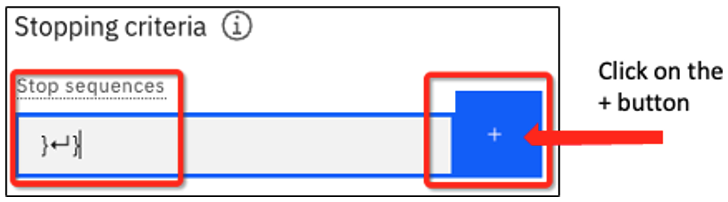
With the stop sequence added, you will see this:

-
Click Generate. You should see the following output:

Now we have valid JSON output. You can remove a Stop sequence by clicking the X.

Lab Summary
- We experimented with the following configuration parameters:
- Temperature - a higher value results in more creativity
- Top P - a lower value means less variability
- Top K - a lower value means less variability
- Top P and Top K both limit the number of tokens that the model will choose from when determining the next token in the sequence.
- We used freeform prompts and Greedy decoding to prompt for a list.
- We generated JSON output and used stop sequences to halt model output.
- It's important to pick the right model for the task at hand, which is not necessarily the larger model. The granite-13b-instruct-v2 model was best suited for both lists and JSON output. Although smaller than the flan models, it was trained by IBM to follow a user's instructions.