204: Implement RAG Use Cases
In this lab, you will review and run examples of LLM applications that implement the Retrieval Augmented Generation (RAG) pattern of working with LLMs. We will expand on the concepts that you learned in the previous labs.
Heads Up! Quiz material will be flagged like this!
Required software, access, and files
- To complete this lab you will need access to watsonx.ai
- Some knowledge of Python
RAG Overview
RAG (Retrieval-Augmented Generation) is one of the most common use cases in generative AI because it allows us to work with data "external to the model", for example, data that was not used for model training. Many use cases require working with proprietary company data, and it's one of the reasons why RAG is frequently used in generative AI applications. RAG also allows us to add some guardrails to the generated output and reduce hallucination.
RAG can be implemented for various AI use cases, including:
- Question and answer
- Summarization
- Content generation
A "human interaction" analogy of RAG is providing a document to a person and asking them to answer a question based on the information contained within.
RAG is "an application pattern" that can be implemented with multiple technologies. However, there are two key steps:
- During the retrieval step, we searched through a knowledge base (documents, websites, databases, etc.) to find information relevant to the instructions sent to the model. Retrieval can be based on keyword search or more advanced algorithms, like semantic similarity.
- The generation step is similar to the generation in non-RAG use cases. The main difference is that information retrieved in the first step is provided as "context" (included in the prompt). Prompting the model to rely on "retrieved context" only, in contrast to the general knowledge which was used to train the LLM, is the key step for preventing hallucinations.
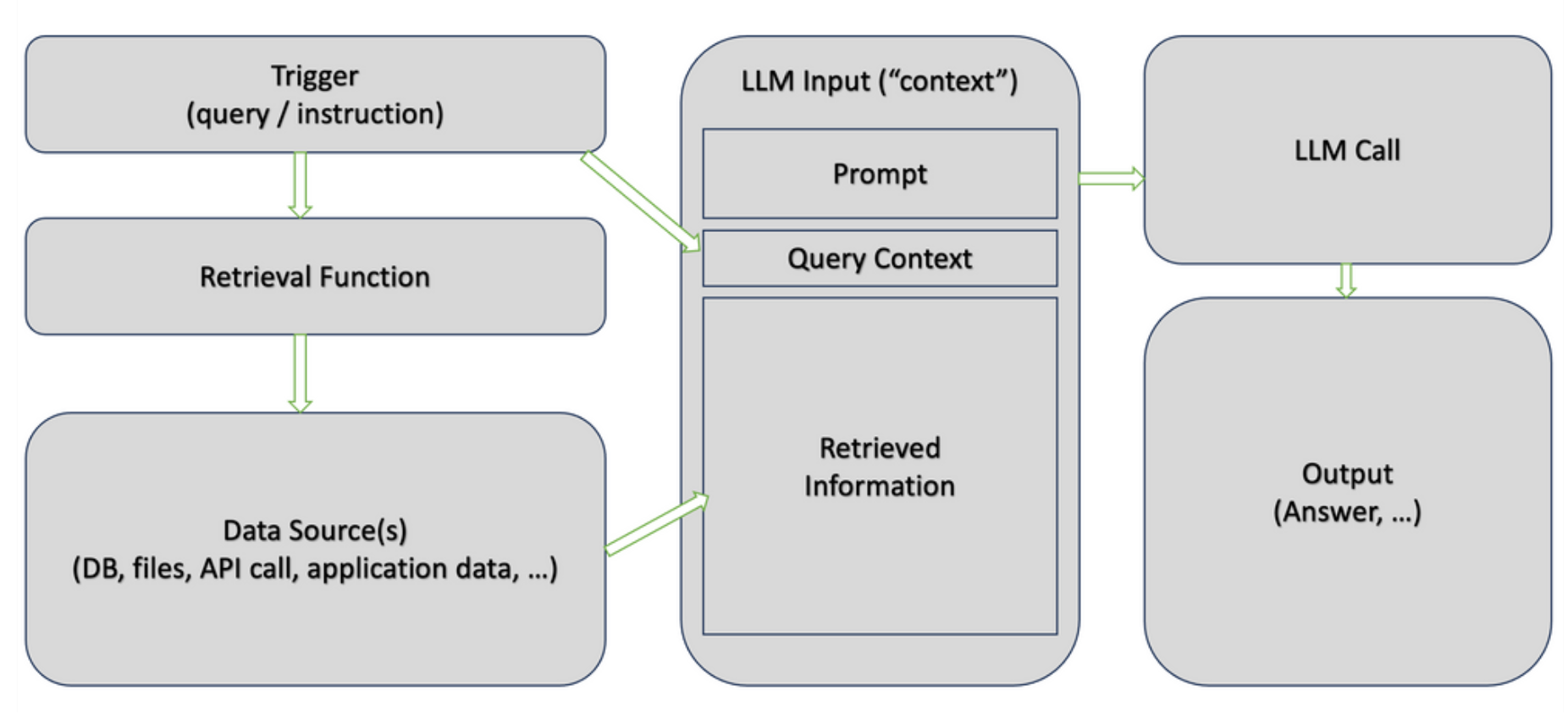
Vector databases
The "knowledge base" for the retrieval step is typically implemented as a vector database. Vector databases are not new, they have been used for several years for semantic search.
Semantic search is a search technique that aims to understand the intent and context of a user's query. It's more advanced than traditional keyword-based search, which relies on matching specific keywords.
Some popular vector databases are:
- Chroma (open-source)
- Milvus
- Elasticsearch
- SingleStore
- Pinecone
- Redis
- Postgres
Some vector databases, like _Chroma, are in-memory databases, which makes it a good choice for experimenting and prototyping RAG use cases. In-memory databases do not need to be installed or configured. This is because all of their data is stored in volatile memory for the duration of the program's runtime. The downside of this though is that we will need to load the data each time we run the application.
Vector databases store unstructured data in a numeric format. For AI use cases, we use a specific term to describe the converted unstructured data - embeddings. Embeddings are created by using an embedding model, for example, a popular open-source model _word2vec__.
One of the key features of embeddings is the ability to preserve relationships. With embeddings, words can be "added and subtracted" like vectors in math. One of the most famous examples that demonstrate this is the following:
king - man + woman = queentxt
In other words, adding the vectors associated with the words king and woman while subtracting man is equal to the vector associated with the word queen. This example describes a gender relationship.
Another example might be:
Paris - France + Poland = Warsawtxt
The vector difference between Paris and France here captures the concept of a capital city.
Here's an example of a semantic search for the word "education". Notice the "nearest point" words in the table. The measurement is in numbers because the search was performed using vector (numeric) data.
You can experiment further with this here.
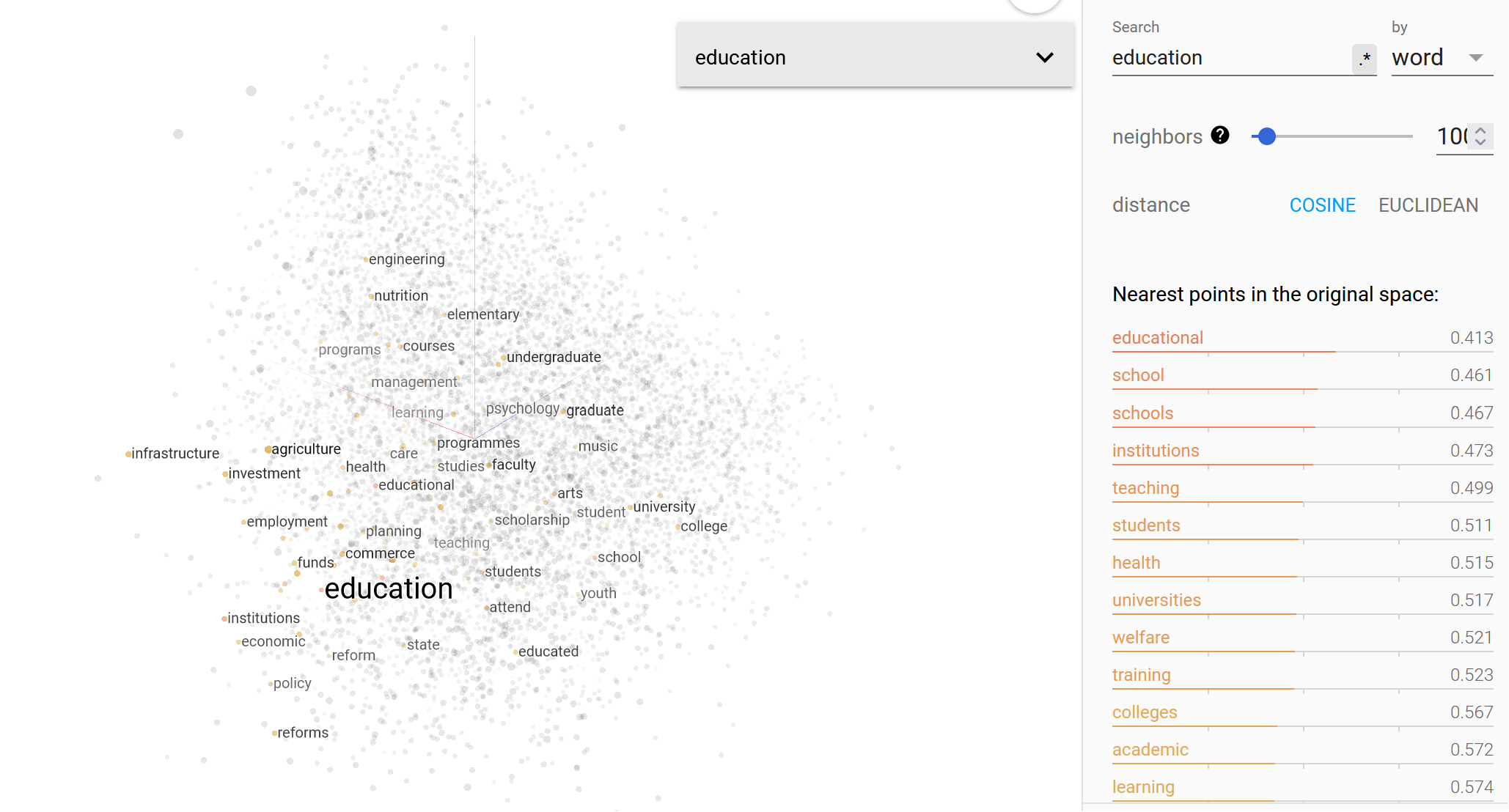
Based on what we have discussed so far, we can make the following conclusions:
- We have a choice of vector databases for implementations of RAG use cases
- We have a choice of several embedding models for converting unstructured data to vectors
- Retrieval of relevant information is the first step in the RAG pattern, and the quality may be affected by the choice of a vector database and an embedding model.
Heads up! Parts of this section will be on the quiz.
In addition to the mentioned factors, loading data into the vector database requires "chunking", which is the process of dividing text into sections that are loaded into the database. There is no single guideline for defining chunks because the best size depends on the content we're working with.
For generative AI use cases, we typically start with _fixed-size chunks, which should be "semantically meaninguful". For example, if in your document each paragraph has approximately 200 words, convert the number of words to several tokens (may vary per LLM), and use this number as the starting chunk size. In addition to the size of the chunk, we also need to specify overlapping (the same information in more than one chunk).
Model providers should publish information on recommended chunk size and overlap percentage for specific use cases. However, even if this information is published, developers will still need to experiment to find the optimal chunk size. If you can't find information on the recommended overlap, you can start with 10 percent (specified in the format of "number of tokens", for example, 100 if your chunk size 1000).
To summarize, we should follow these steps when implementing the RAG use case:
- Select a vector database. When working with watsonx.ai, we should confirm that the selected vector database is supported. Check IBM documentation for the latest updates.
- Select the embedding model. Confirm that the embedding model works with the selected vector database.
- Experiment with chunk size.
As we discussed earlier, the second part of the RAG use case, sending instructions to LLM, is similar to non-RAG patterns. Developers should pay special attention to token limits because retrieved content will be added to the prompt. If the token limit is exceeded on input, then the model will not be able to generate output. This check will need to be implemented as "custom code" in your LLM applications.
WML API does return errors if token size is exceeded.

RAG on documents with LangChain and ChromaDB
To run the lab for this section we will start by logging into the watsonx platform; after navigating to the watsonx home page here, we will want to open the Notebook editor that we can use to run the notebook associated with this lab.
If you don't know how to acccess watsonx.ai or are unsure how to open to the notebook editor, follow this reference link which will walk you through the process for accessing watsonx.ai and opening the Jupyter notebook editor.
Use the following values for this lab:
- Name:
{uniqueid}-rag-chromadb - Notebook URL:
https://raw.githubusercontent.com/ibm-build-lab/VAD-VAR-Workshop/main/content/labs/Watsonx/WatsonxAI/files/204/use_case_rag.ipynb
After your notebook is launched and created, you can follow along and run through each cell of the notebook to complete the lab. The notebook contains comments explaining what code in each cell does as well as any necessary input that you might need to provide to successfully run a cell.
Good luck!
RAG using a website (optional)
This notebook is very similar to the last one. However, unlike the previous instead of sourcing the content from a given file you will instead implement a web scraper that allows a question to be answered about a given webpage.
This notebook can be run within the watsonx platform; after navigating to the watsonx home page here, we will want to open the Notebook editor that we can use to run the notebook associated with this lab.
If you don't know how to acccess watsonx.ai or are unsure how to open to the notebook editor, follow this reference link which will walk you through the process for accessing watsonx.ai and opening the Jupyter notebook editor.
Use the following values for this lab:
- Name:
uniqueid-rag-web-chromadb - Notebook URL:
https://raw.githubusercontent.com/ibm-build-lab/VAD-VAR-Workshop/main/content/labs/Watsonx/WatsonxAI/files/204/use_case_rag_web.ipynb
After your notebook is launched and created, you can follow along and run through each cell of the notebook to complete the lab. The notebook contains comments explaining what code in each cell does as well as any necessary input that you might need to provide to successfully run a cell.