Integrating VectorDB with watsonx.ai foundation models
This lab will show you how we can use watsonx.ai and a Vector Database together to solve a Retrieval Augmented Generation (RAG) use case. By combining watsonx.ai LLM's (Large Language Model) foundation models with an existing knowledge base of data we can provide insightful context for our watsonx foundation models when generating an answer; in this case we will make use of a PDF to provide additional context to prompts given to our watsonx.ai foundation model.
What is RAG?
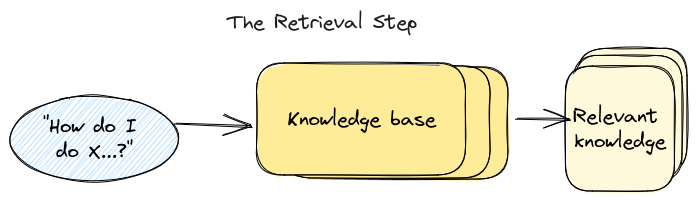
In the previous lab we discussed what RAG or Retrieval Augmented Generation is, for a quick recap, RAG is an AI framework for improving the quality of LLM-generated responses by grounding the model on external sources of knowledge to supplement the LLM’s internal representation of information.
What are embeddings and why use a VectorDB?
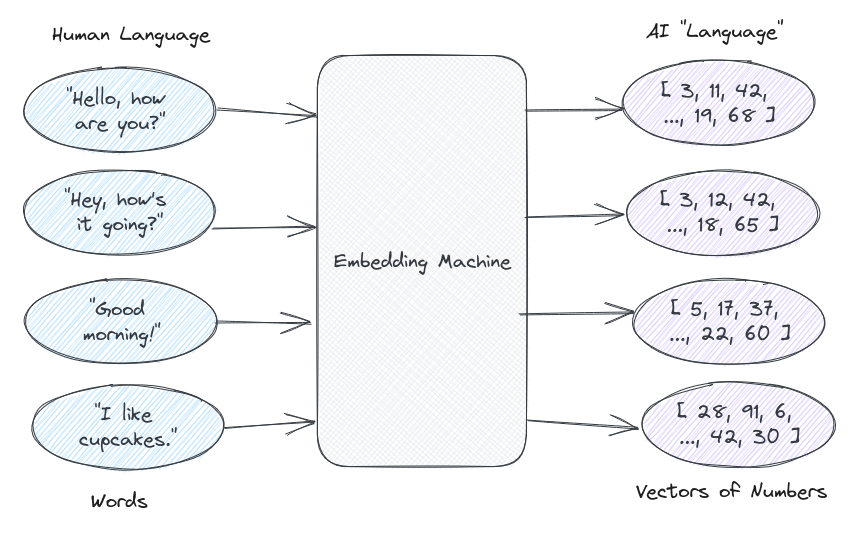
To set a baseline, a vector database (Vector DB) is specialized databases which is used for storing data in vectorized format, mostly commonly in the form of arrays with different pairs of numbers. The next question might be Why use a Vector DB?; to understand that we first need to understand what embeddings are. Human language is very complex, the human brain is capable of understanding when we use words that mean the same thing or understand that certain words belong to a specific group. For example, our brains are able to understand that "red" and "blue" are both colors despite them being different words, we can also understand that when someone uses the words "happy" and "joyful" they generally represent the same emotion or feeling depsite them being two very different words. Trying to explain that to a machine is very difficult, but LLM's try to mirror some of this complexity in their own way, through a complex understanding of numbers. In short, an LLM tries to understand human language in a format that makes sense to machines, groups of numbers. Without getting to complicated LLM's use a translator to convert human language into numbers that it can easily associate with, this translator is usually an embedding function, and the output is a vector of numbers known as embeddings. A simple example of this might be the the phrase "Good morning" represented as the following [34, 12, 234, 638, 12, ...].
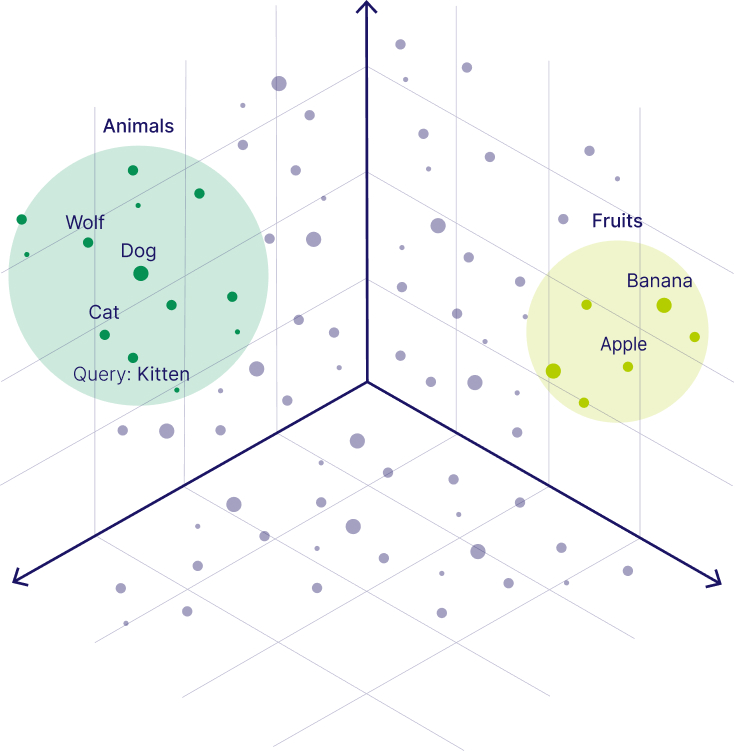
While to humans, this might not make any sense, it's meaningful to a machine because these numbers represent a sort of comprehesion for a machine to properly understand human language. These vectors can be plotted on a graph as they can represent coordinates which can be plotted, from these coordinates we can determine how close two embeddings, or two pieces of text, are to one another; this idea of closeness is a core principle behind semantic search, which we use when we want to query or look through all of our stored embeddings for text (or embeddings) similar to our query. Now comes our VectorDB, it stores all of our embeddings (along with associated metadata) and conceptually acts as a plot of all of the vectors that we have stored; when we make a query against our VectorDB it can return the embeddings that are closest (shortest distance) to our query from the plot. A simple visual representation of this can be seen in the image below:
What is Chroma DB?
ChromaDB (or Chroma) is marketed as a database for building A.I applications, but at its core can be simplified as a database for storing vectorized data as embeddings. The distinction for embeddings is important because embeddings have emerged to become the A.I-native way to represent any kind of data (i.e. text, video, images), making them ideal for working with all kinds of A.I-powered tools and algorithms. One things that makes Chroma unique from other embeddings database is its lightweight nature allowing it to be run in-memory if there is no need persistence. Being lightweight also lends Chroma to be fast, easily scalable (by supporting other traditional databases for persistence) and easy to use SDKs integration using Python and Javascript.
Putting it all together... RAG with VectorDB
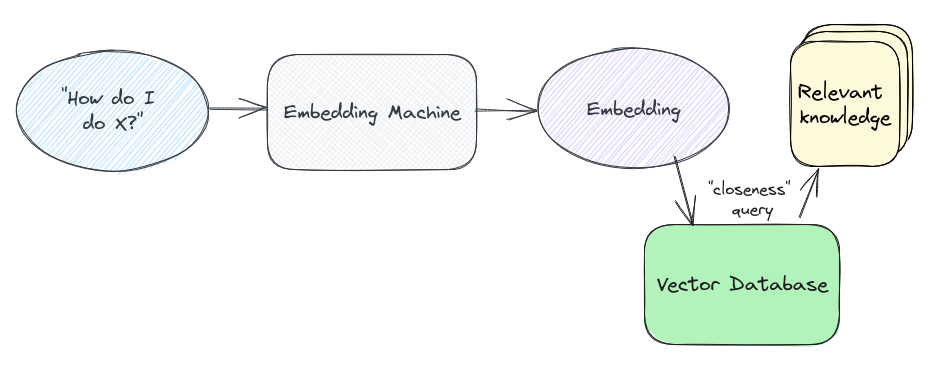
Now the we have enough background information, we can put it all together and try to understand from a high-level how the pieces for RAG using Vector DB fit together. As discussed previously, Retrieval Augmented Generation (RAG) is an approach used to improve the context provided to an LLM (Large Language Model) in generative AI use-cases, including chatbot and general question-answer applications. The vector database is used to enhance the input prompt passed to the LLM by adding additional context to the input query. Instead of passing the prompt directly to the LLM, in this case watsonx.ai, in the RAG approach you follow the steps below:
-
Generate embeddings, which are output as vectors, from an existing dataset that serves as the knowledge base - This dataset, which adds additional context to the LLMs response, can come in the form of product documentation, research data, technical specifications, product catalog and descriptions, and even more.
-
Store the output embeddings from the previous step into a Vectorized database. Vectors are easy to index and can be queried very fast.
When a user initiates a prompt, instead of passing it directly to the LLM, we augment it with additional context:
-
The user prompt is passed into the same embedding model used for our dataset, returning a vector embedding representation of the query.
-
This embedding is used as the query (semantic search) against the vector database, which returns similar vectors.
-
These vectors are used to look up the content they relate to (if not embedded directly alongside the vectors as metadata).
-
This content is provided as context alongside the original user prompt, providing additional context to the LLM and allowing it to return an answer that is likely to be far more contextual than the standalone prompt.
With all those pieces together you can complete a RAG use-case using Vector DB however, there other ways to complete RAG.
Comparing with Watson Discovery
In the previous lab we completed a RAG use-case using Watson Discovery; in this lab we make use of a Vector database instead. While both fo these techniques can be used to achieve the same thing, they differ in their approach. Watson Discovery is primarily used as a document understanding and analysis platform, this works out very well in scenarios where large numbers of documents are used or needed to make business decisions. For example, a large corporation sifting through larges amounts of company financial documents to determine insights before making a merger or acquisition; or a law firm sifting through briefings and other law documents to conduct legal research for legal precedents. Vector databases work a bit different by creating embeddings, or arrays of large numbers, from tokens of text which are then stored into a database and can be quickly referenced when a similar embedding query of user input is supplied to the vector database. Both solutions achieve the same results for determining context, however they way they are impletmented is their biggest differentiator. With Watson Discovery, you can make use of a managed service and sleek UI to ingest and even annotate documents for future Natural Language queries; given its managed nature Watson Discovery also proves to be an easier tool to integrate into other servies using a simple API Key, Service URL, and Project ID; however, this simplicity comes at the cost of granular control. Vector databases can used as both as a managed (i.e. PineconeDB) or unmanaged (i.e. ChromaDB) service, unlike Watson Discovery which is only provided as a managed offering. Vector databases also provide more fine tuned controls such as using different embedding models (for vectorization) or tokenizers allowing users to customize the DB to better fit their unique use-case which can be much better approach the general one-size fits all approach of Watson Discovery. This additional controls, does come with added complexity making it harder to easily integrate VectorDB the same way you can with Watson Discovery. Overall both approaches are able to support the RAG model that is becoming popular with LLM's, since you have already completed RAG with Watson Discovery, this lab will explore doing the same with Vector databases.
Run the VectorDB + watsonx.ai lab
To run the lab for this section we will start by logging into the watsonx platform; after navigating to the watsonx home page here, we will want to open the Notebook editor that we can use to run the notebook associated with this lab.
If you don't know how to acccess watsonx.ai or are unsure how to open to the notebook editor, follow this reference link which will walk you through the process for accessing watsonx.ai and opening the Jupyter notebook editor.
Use the following values for this lab:
- Name:
{uniqueid}-rag-chromadb - Notebook URL:
https://raw.githubusercontent.com/ibm-build-lab/VAD-VAR-Workshop/main/content/labs/Watsonx/WatsonxAI/files/rag-with-chromadb.ipynb
After your notebook is launched and created, you can follow along and run through each cell of the notebook to complete the lab. The notebook contains comments explaining what code in each cell does as well as any necessary input that you might need to provide in order to successfully run a cell.
Good luck!